
阿里巴巴通义实验室向全球开源了Tongyi DeepResearch模型。这是全球首个在性能上能与行业标杆OpenAI DeepResearch相媲美,并且完全开源的Web Agent。在多个权威基准测试中,Tongyi DeepResearch不仅表现出色,还在不少单项上名列前茅,刷新了整个AI行业的技术标准。

过去六个月里,通义团队每月发布一篇技术报告。随着Tongyi DeepResearch的正式亮相,他们又发布了六篇新的技术报告,内容涵盖数据合成、长期推理等多个方面,几乎涵盖了智能体技术的所有关键领域。
Tongyi DeepResearch采用了先进的MoE架构,在性能与同等规模的传统稠密模型相当的同时,推理效率提升了近10倍。这意味着高性能AI智能体的部署和使用门槛大大降低。

该模型拥有高达128K的超长上下文窗口,可以一次性处理和记忆大量信息,适用于需要进行长周期、多轮次深度挖掘的研究任务。实际应用中,它能够同时“阅读”并理解数十篇学术论文或浏览数百个网页,还能发现不同文档之间的内在联系,进行综合归纳。

通义团队为这个“大脑”设计了两种不同的推理范式:ReAct模式和IterResearch模式。ReAct模式遵循“思考-行动-观察”的闭环,模型先对问题进行推理,再决定下一步行动,最后观察结果,进入下一轮循环。这种模式受到AI领域“惨痛教训”的影响,强调利用海量计算能力的通用方法。

IterResearch模式则针对极端复杂的深度研究任务。它将任务分解成一系列结构清晰的“研究回合”,每个回合只携带上一回合的核心结论,构建精简的工作空间。这种方法使Agent在执行长期任务时保持清晰的认知焦点和高质量的推理能力。

此外,通义团队提出了Research-Synthesis框架,让多个并行的IterResearch Agent同时研究同一复杂问题,最终整合各自的报告和结论,得出全面准确的答案。

Tongyi DeepResearch的成功还在于其背后的训练方法论。通义团队重新发明了从预训练、微调到强化学习的整个流程,构建了一个完整的端到端训练闭环。核心系统是AgentFounder,实现全自动高质量合成数据生成,降低了传统人工标注数据的成本和生产效率低下的问题。

在预训练阶段,团队引入了Agentic CPT,为后续训练打下基础。数据合成分为两步:数据重组和问题构建,以及动作合成。通过这些步骤,模型能够在真实世界中遇到的各种场景中表现得更好。

后训练阶段,团队采用更精密的端到端合成数据生成方案,确保数据质量和可扩展性。为了应对复杂的真实世界问题,团队设计了一种新颖的流程来合成基于Web的问答数据,增加了问题难度。
为了提高模型的实践能力,团队采用了GRPO算法进行强化学习,并优化了策略梯度损失函数,确保学习信号与模型当前能力匹配。团队还创建了高仿真的训练环境和统一的工具沙盒,确保智能体在训练和评估期间稳定调用各种工具。
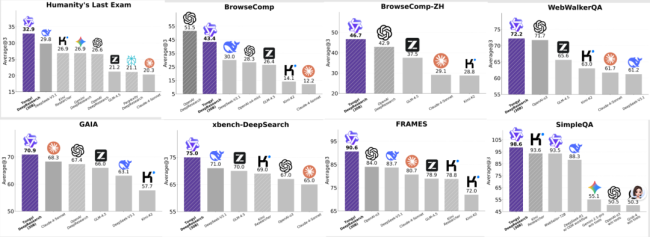
Tongyi DeepResearch在多个评测集上取得了优异成绩。例如,在Humanity's Last Exam评测集中,它比OpenAI o3高出8分。在BrowseComp系列和xbench-DeepSearch评测中,也展现了强大的信息检索和综合分析能力。
该模型已在高德地图和法律领域成功落地。在高德地图App中,它结合实时交通、天气等信息,提供智能导航服务。在法律领域,通义法睿能够自动检索相关法条和案例,进行深度归纳和分析,在国际顶尖模型同台竞技中表现最优。
除了这些应用,Tongyi DeepResearch在学术研究、市场分析、政策研究、金融分析等领域也有广阔的应用前景。它采用了Apache-2.0许可证,降低了企业和个人开发者二次开发的法律门槛和商业风险。开放的技术生态有助于形成统一的技术标准和最佳实践,推动技术进步。




