2月6日,据外媒报道,李飞飞等『斯坦福大学』和华盛顿大学的研究人员以不到50美元💵的费用,使用了16张『英伟达』H100 GPU,耗时26分钟就完成了训练,成功“打造”出了一个名为s1-32B的人工智能推理模型。
根据李飞飞等人的研究论文《s1: Simple test-time scaling》,该模型在数学和编码能力测试中的表现,与OpenAI的o1和『DeepSeek』的R1等尖端推理模型不相上下,在竞赛数学问题上的表现更是比o1-preview高出27%。
凭借低成本、高效能,s1模型成为继“AI界价格屠夫”『DeepSeek』之后再次引发科技界热议的话题。
但s1推理模型的成本真的只有50美元💵吗?其性能是否真有描述的那么出色?在“白菜价”的背后,李飞飞团队又有哪些探索?
针对成本问题,复旦大学计算机学院副教授、博士生郑骁庆在接受《今日霍州》记者采访时指出,“像『DeepSeek』或者类似的公司,在寻找有效的整合解决方案时,需要进行大量的前期研究与消融实验。”这意味着前期是需要大量“烧钱”的。
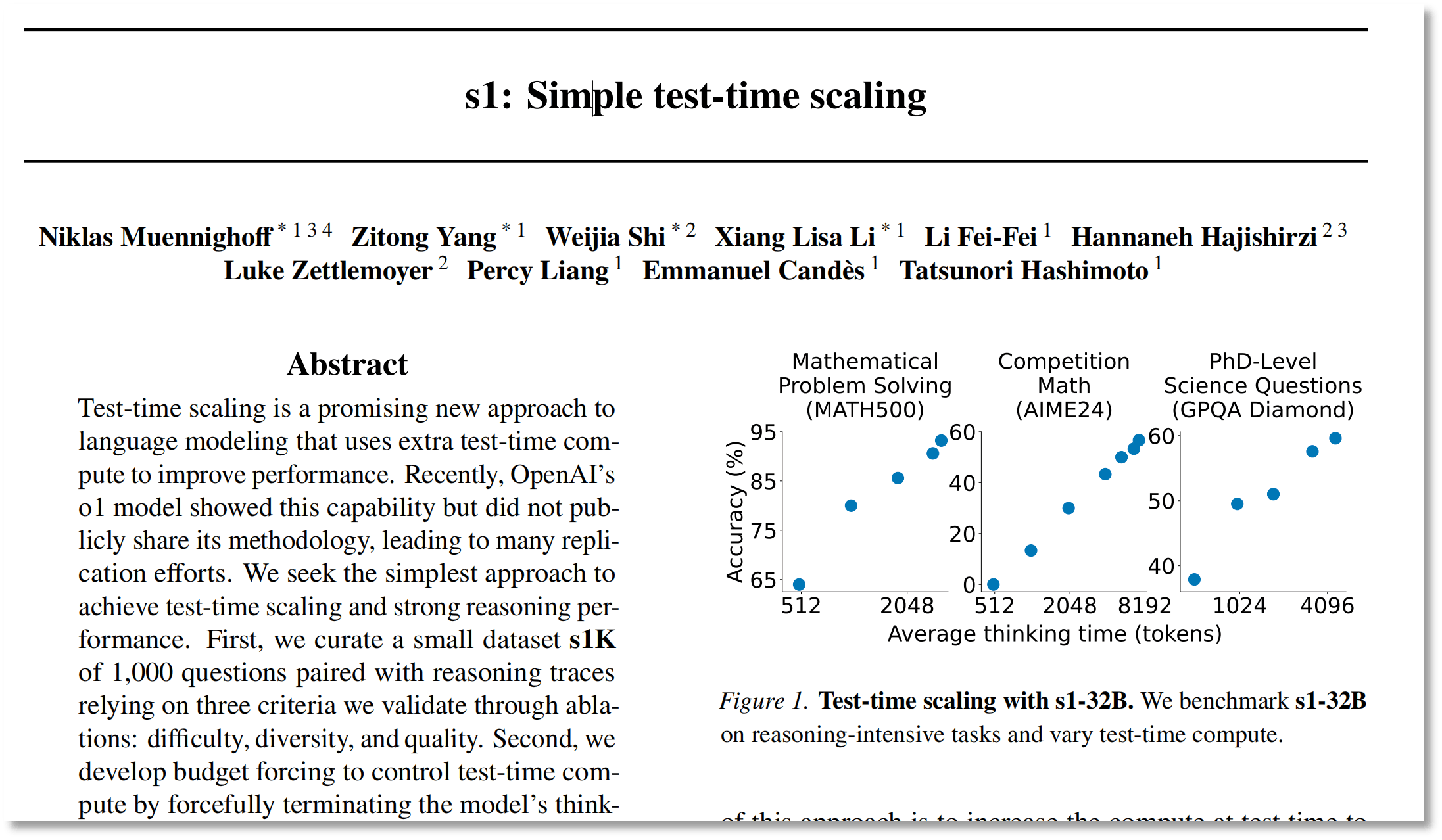
图片来源:论文《s1: Simple test-time scaling》
疑问一:只花了50美元💵?
据报道,李飞飞等『斯坦福大学』和华盛顿大学的研究人员以不到50美元💵的费用,使用了16张『英伟达』H100 GPU,耗时26分钟就完成了模型s1-32B的训练。
参与该项目的『斯坦福大学』研究员尼克拉斯·穆宁霍夫(Niklas Muennighoff)更是表示,如今,只要约20美元💵就能租到所需的计算资源。
然而,关于训练成本,有几点需要明确。
首先,模型s1-32B的打造并非是从零开始,而是基于现成的、预训练的模型(阿里『通义千问』Qwen2.5-32B-Instruct)进行监督微调。而微调一个模型和从零开始训练一个模型的成本是无法相提并论的。
jrhz.info其次,50美元💵是否包含了其他数据、设备、消融实验等费用,还要打一个问号。正如『DeepSeek』-V3不到600万美元💵的训练成本,实际上也只包括了训练时的GPU算力费用。
郑骁庆向每经记者表示,“像『DeepSeek』或者类似的公司,在寻找有效的整合解决方案时,需要进行大量的前期研究与消融实验。”
而消融实验就意味着,前期是需要大量“烧钱”的。
AI数据公司Databricks研究员奥马尔·哈塔布(Omar Khattab)评价称,(李飞飞团队的)论文似乎是关于Qwen模型的某种发现。
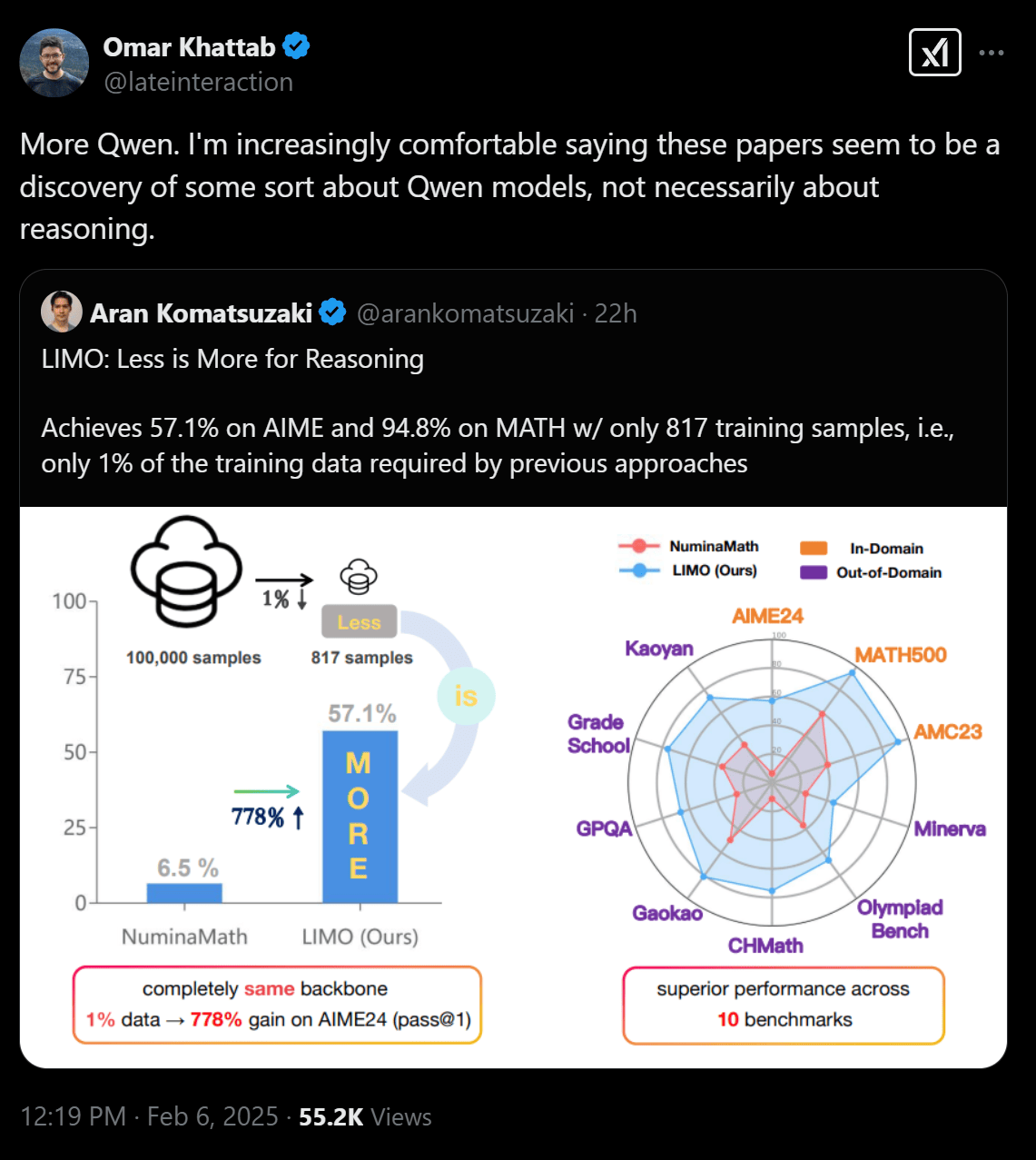
图片来源:X
今日霍州DeepMind资深研究员Wenhu Chen同样表示,“真正神奇的是Qwen模型。我们尝试过把基座模型换成其他模型,用同样的数据去训练,但最终并不能达到这么好的效果。”
也就是说,s1-32B是站在了“巨人肩膀”上,且50美元💵的成本也并没有涵盖Qwen模型的训练费用。
疑问二:超过OpenAI的o1和『DeepSeek』-R1?
李飞飞团队发表的论文提到,根据Qwen2.5-32B-Instruct进行微调的s1-32B模型,在数学和编码能力测试中的表现,与OpenAI的o1和『DeepSeek』的R1等尖端推理模型不相上下,在竞赛数学问题上的表现更是比o1-preview高出27%。
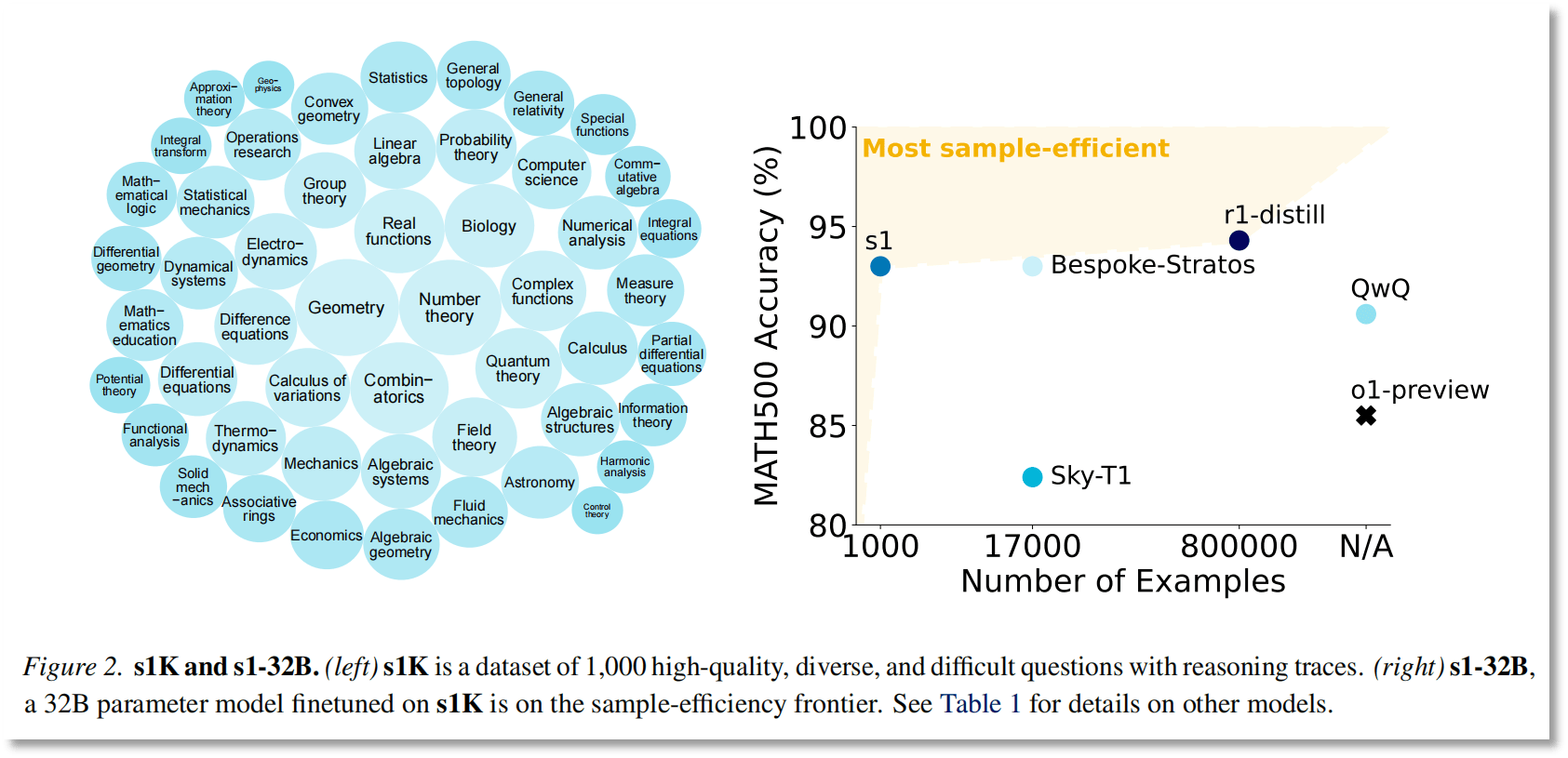
图片来源:论文《s1: Simple test-time scaling》
此外,研究结果显示,s1-32B是样本效率最高的开放数据推理模型,表现明显优于其基座模型(Qwen2.5-32B-Instruct)以及OpenAI的推理模型o1-preview。
事实上,s1-32B只能在特定的测试集上超过o1-preview,且并没有超过“满血版”o1和『DeepSeek』-R1。
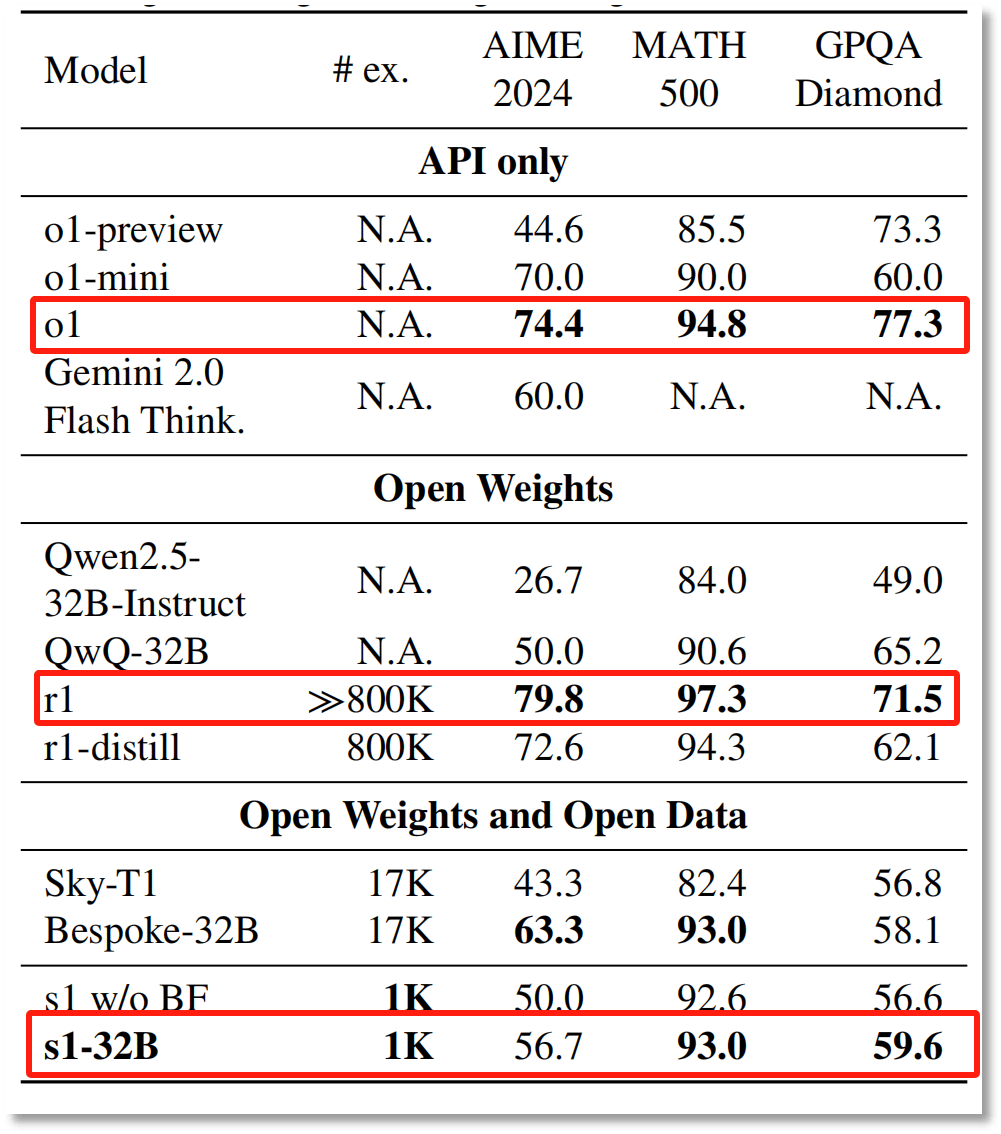
图片来源:论文《s1: Simple test-time scaling》
研究结果显示,在AIME 2024和MATH 500两个测试集中,s1-32B超过了o1-preview,但无论在哪个测试集,s1-32B都没有超过“满血版”o1正式版『DeepSeek』-R1。
“白菜价”模型的背后
测试时拓展:多动脑多检查
事实上,李飞飞团队论文的核心也并不在于如何“卷”模型价格,而是研究如何以最简单的方式实现“测试时拓展”(test-time scaling)。
测试时扩展是一种在模型推理阶段通过多步推理来提高模型性能的技术。具体来说,研究团队通过预算强制,控制模型可以“思考”多长时间或进行多少步操作。如果模型过早结束推理,系统会鼓励模型延长思考时间,确保其充分考虑问题。这也就意味着,模型在推理时会进行多次推理迭代,并逐步优化推理结果,最终生成高质量的答案。
例如,当被问到“raspberry”中有几个“r”时,模型首先进行了初步推理,并得出了错误的初步结果:有2个r。但推理过程并没有就此结束,模型又重新进行推理,优化了上次回答的结果,输出了最终的答案:3个r。

图片来源:论文《s1: Simple test-time scaling》
OpenAI的o1系列模型就是一个典型的例子,展现了测试时拓展在模型性能提升上的潜力。
微软CEO萨提亚·纳德拉(Satya Nadella)曾表示,我们正在见证一种新的规模法则(Scaling Law)的出现——模型效率与测试时间或推理时间计算有关。
高质量数据集s1K:数据炼金术
此外,李飞飞研究团队还从16个来源收集了59029道高质量题目,包括数学竞赛问题、博士级别的科学问题、奥林匹克竞赛问题等,并通过三个标准进行验证:难度、多样性和质量。
通过过滤,研究团队最终得到了包含1000个样本的s1K数据集,数据集覆盖几何、数论、量子力学等50个领域,并且每个问题都配有从Google Gemini 2.0 Flash Thinking Experimental作为“教师模型”蒸馏而来的的答案和推理轨迹。
这个数据集的构建基于三个关键标准:难度、多样性和质量。
高质量的数据集,极大降低了s1-32B模型的训练成本。
复旦大学计算机学院副教授、博士生郑骁庆在接受每经记者时表示,大规模的数据可能不会成为下一步大家争夺的战场,其成本和产出之间的比例在慢慢压缩,而高质量数据的微调和强化学习未来将会有更多的投入。
今日霍州




