
本文的第一作者Yu Wang来自加州大学圣地亚哥分校,主要研究方向为Memory for LLMs and Memory for LLM Agents. 该论文于2024年在MIT-IBM Waston Lab实习过程中完成,通讯作者Zexue He也毕业于加州大学圣地亚哥分校。
M+ 是在 MemoryLLM 之上提出的长期隐空间记忆扩展框架:通过把「过期」隐藏向量写入 CPU - 侧长期记忆池,再用协同检索器拉回最相关记忆,它将 8 B 级模型的有效记忆跨度从原本不到 20 k tokens 提升到 160 k tokens 以上,同时显存占用保持不变。

- 论文标题:M+: Extending MemoryLLM with Scalable Long-Term Memory
- 论文链接:https://arxiv.org/abs/2502.00592
- 代码仓库:https://github.com/wangyu-ustc/MemoryLLM
- 开源模型:https://huggingface.co/YuWangX/mplus-8b
背景:上下文 ≠ 记忆 & 现有记忆模型的缺陷
上下文窗口并不能直接等价于记忆。 GPT-4.1 之类的模型即便支持 100 万 token,也会随窗口线性升高显存与延迟,难以落地本地部署。
业界主流做法是 “Token-Level Memory”:把历史内容或三元组存在数据库 / 向量库,检索后再拼接回 prompt;MemGPT 等系统即属此类。该类做法不需要重复训练,直接结合 GPT-4 这样的大模型便可以获得很不错的性能,但是,它也会有一些随之而来的问题:(1) 冗余:原始文本并非最紧凑表达,重复率高。(2) 冲突难解:遇到相互矛盾或不断更新的信息时,文本级冲突消解复杂。(3) 多模态能力弱:由于数据库格式为文本,处理音频或者图片,视频数据将相对困难。
jrhz.info因此,我们希望探索隐空间 (Latent-Space) 的 Memory -- 既压缩又可端到端训练,更接近人类在神经激活中存储信息的方式。
M + 的关键改进:Long-Term Memory
在 MemoryLLM 中,我们为 8B 的 Llama3 模型引入了约 1.67B 的 Memory。Llama3-8B 的 Transformer 共包含 32 层。当第一层接收到词输入后,会通过 Embedding 层将词转化为一系列 4096 维的向量。基于这一特点,我们设计了 MemoryLLM,在每一层都加入 N 个 Memory Tokens(实验中 N=12800)。在生成过程中,这些 Memory Tokens 会作为每一层的 Prefix,通过 Cross-Attention 将信息注入后续层,使模型能 “看到” 保存在 Memory Pool 中的历史信息。
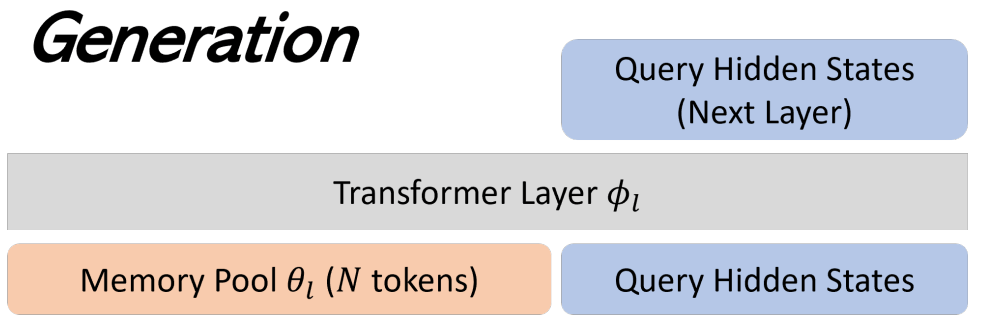
在更新阶段,我们会将每层 Memory Token 中最后 K 个(实验中 K=256)与需要写入的信息一同送入 Transformer,再次经过 Cross-Attention,将信息压入新的 Memory Tokens 中(如下图所示)。与此同时,我们在原有 Memory 中随机丢弃 K 个旧 Token,并将新生成的 K 个 Token 放到 Memory 尾部,完成更新。
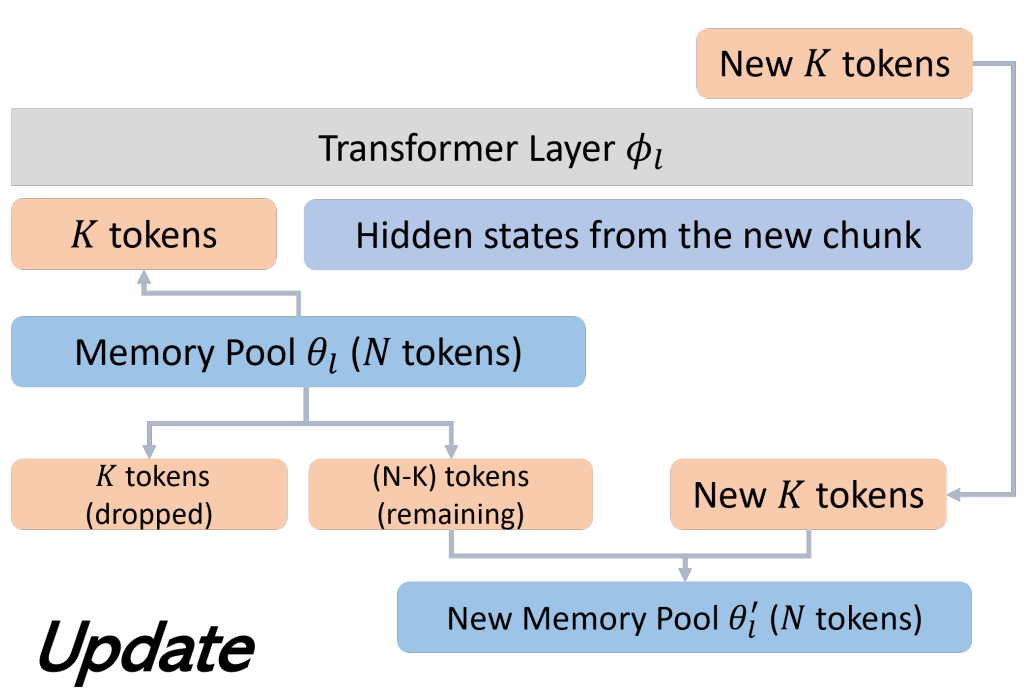
基于这样的设计,借助每层 12800 个 Memory Vectors,我们在 50k tokens 内都能保持良好的信息留存(最早 MemoryLLM-7B 版本只做到 20k,后续在 GitHub 提供的新版模型 https://github.com/wangyu-ustc/MemoryLLM 可达 50k)。然而,这样的记忆容量仍无法满足我们对更长序列的期待。要进一步扩展 Memory,单靠原有的 1.67B 容量已远远不够,因此我们提出了 Long-Term Memory。
如何高效实现 Long-Term Memory?考虑到 MemoryLLM 中每一个 Memory Token 本质上都来自 Hidden States,我们将那些在更新过程中被 “丢弃” 的 Memory Token 并非直接舍弃,而是将其保存在长期记忆池中(如下图)。
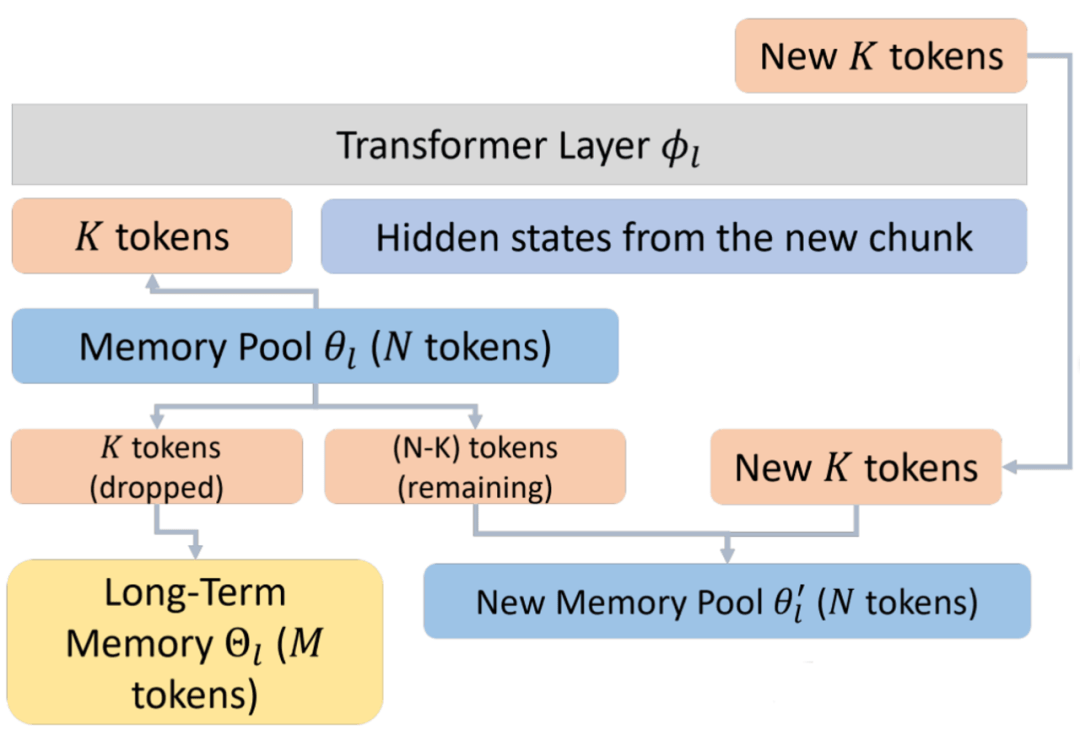
仅仅保存是不够的,我们还需要具备强大的提取能力。最初我们尝试用 Attention 来从长期记忆中检索 Hidden States,但实验表明 Attention 在提取 Hidden States 时效果有限(在论文的消融实验中做了详尽对比)。因此我们提出协同提取器(Co-trained Retriever),并与全模型进行联合训练(如下图)。
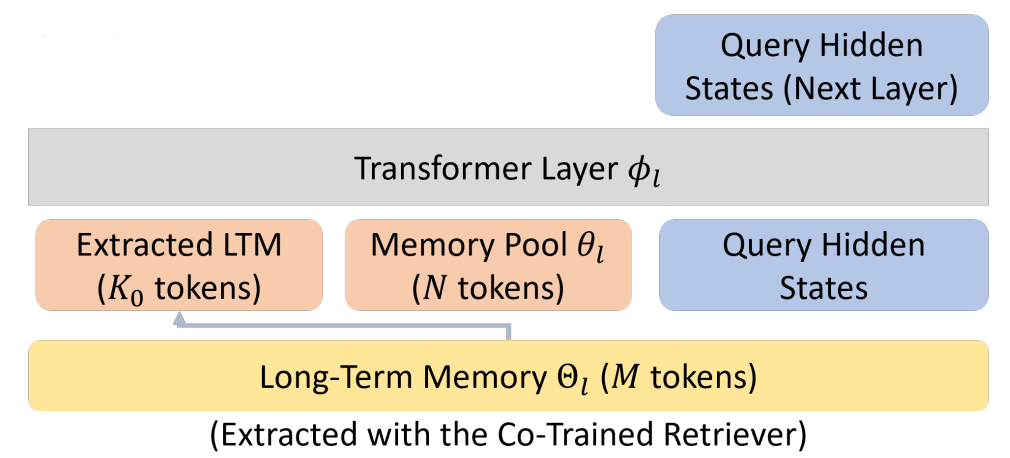
通过这一结构,我们将模型的有效记忆跨度从 50k 一举提升到 160k,且由于 Memory 主要驻留在 CPU,不会显著增加 GPU 负担。
M + 的实验结果
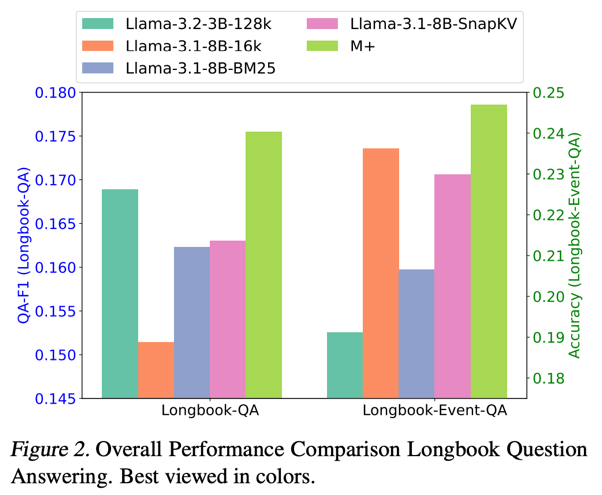
显著性能提升及更少的 GPU 使用:在 Longbook-QA 和 Longbook-Event-QA 两个数据集上,我们都在更少 GPU 的使用下(单卡 18GB 左右)获得了更强大的性能。

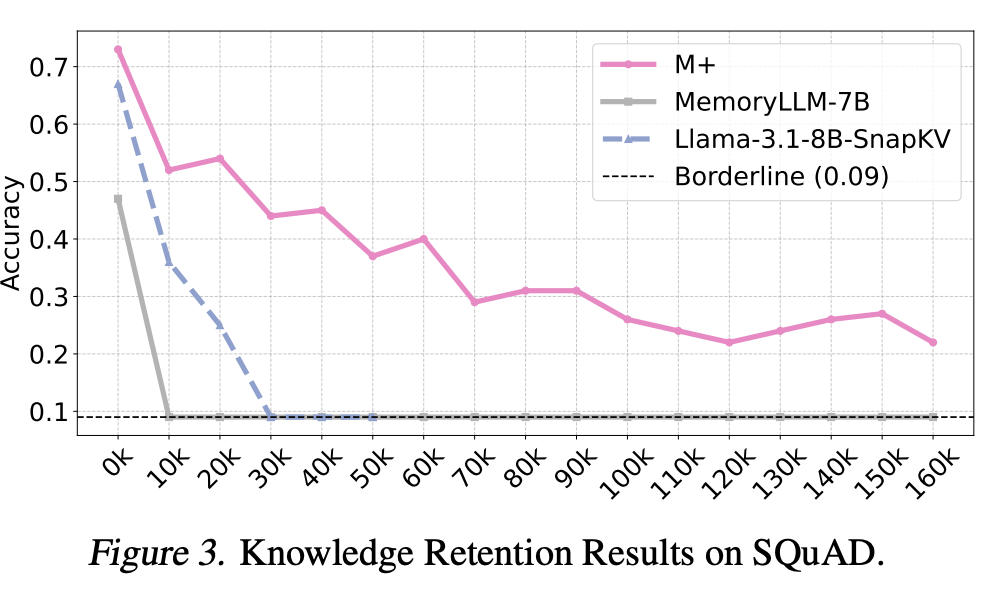
更强的信息留存能力:在 SQuAD 数据集上表现出远超 MemoryLLM-7B 以及相关 ablation baseline 的信息留存能力,可以达到 160k 依旧不完全遗忘过去的信息。
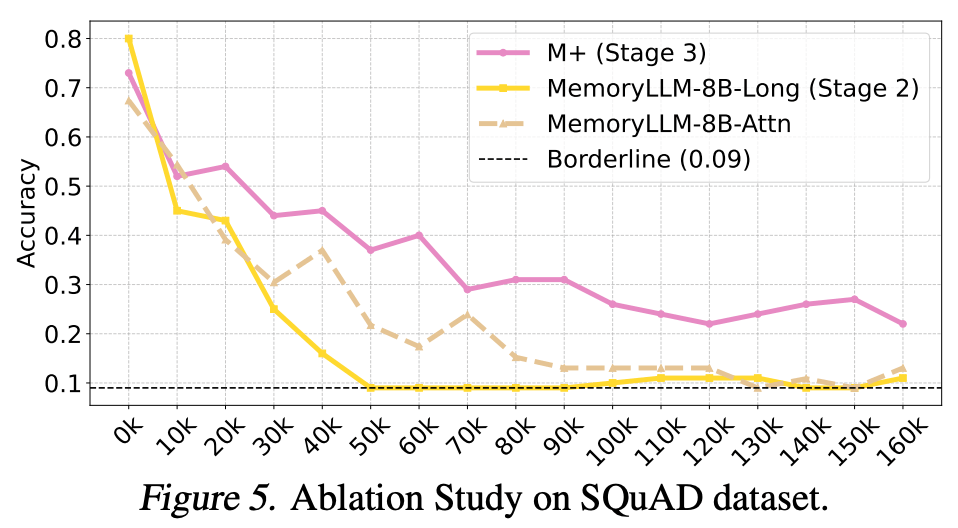
结语
M+ 展示了我们在探索隐空间长期记忆领域的重要进展,也为下一代具备持续记忆能力的语言模型提供了坚实的技术支撑。未来,我们将继续研究更高效的存储机制、更智能的检索策略,以及与多模态输入更自然融合的隐空间记忆架构。在此方向上,M+ 不仅是对 MemoryLLM 的一次扩展,也是我们对 “让模型拥有接近人类记忆能力” 这一愿景的又一次有力实践。




