随着企业『数字化』进程的加速,合同作为商业活动的核心载体,其管理效率与风险控制能力直接关系到企业的运营成本与合规安全。传统的光学字符识别技术虽能实现基础的文本『数字化』,但面对合同文档复杂的版式、非结构化内容以及专业的法律语义,显得力不从心。本文旨在从一款企业级合同OCR智能产品的角度出发,系统性地阐述如何整合当下最先进的深度学习OCR模型与自然语言处理技术,构建一个端到端的合同智能处理系统。该系统不仅实现高精度的文字识别,更核心的能力在于对合同关键信息(如主体、金额、日期、责任条款等)的精准抽取、结构化呈现,并提供高效的合同版本比对功能。本文将详细剖析其核心技术架构,包括基于深度学习的文档图像预处理、融合视觉与文本特征的多模态信息抽取、以及基于预训练语言模型的语义理解与比对,并最终展示其在合同审核、风险管控和知识沉淀等场景下的产品化应用与价值。
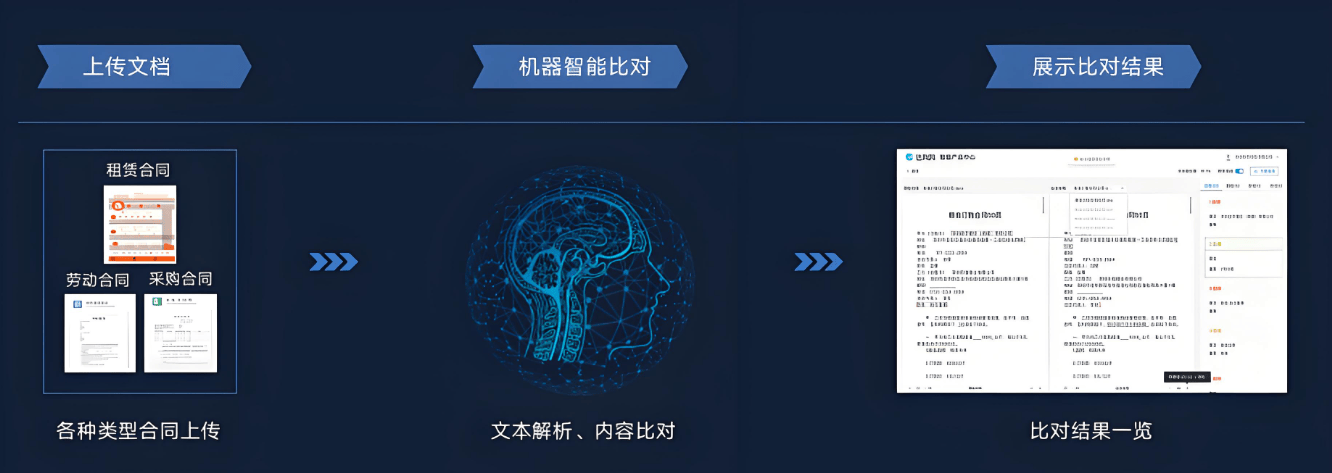 合同比对OCR
合同比对OCR
关键词: 合同OCR;智能信息抽取;文档智能;深度学习;自然语言处理;合同比对;多模态学习
1. 引言
在商业环境中,合同是企业运营的基石。然而,合同管理长期面临着处理效率低下、人工审核易出错、版本管理混乱、风险点隐藏深等痛点。尽管OCR技术为纸质或扫描版合同的『数字化』提供了可能,但传统OCR方案存在明显局限:(1)对复杂版式(如表格、印章、多栏排版)适应性差;(2)识别结果仅为纯文本流,丢失了文档结构与语义信息;(3)无法理解合同内容,无法直接服务于业务场景。
因此,一款现代化的合同OCR产品,其核心目标已从“看得准”升级为“看得懂”。它需要成为一个集感知(文字识别)、理解(语义解析)、决策(风险提示) 于一体的智能系统。这迫切需要将计算机视觉领域的先进OCR模型与NLP领域的语义理解技术进行深度融合。
2. 核心技术架构
我们的合同智能处理系统采用分层、模块化的设计,其核心流程与技术选型如下:
2.1 文档图像预处理与增强
jrhz.info合同文档质量参差不齐,存在倾斜、噪点、阴影、褶皱等问题。我们采用基于深度学习的图像处理模型:
- 文档矫正: 使用基于CNN的角点检测网络(如DewNet)自动检测文档边界并进行透视变换矫正。
- 图像增强: 采用生成对抗网络,如CycleGAN或U-Net结构的去噪、二值化模型,有效提升低质量扫描件的图像质量,为后续识别奠定基础。
2.2 融合视觉与布局信息的智能OCR识别
此阶段是连接“图像”与“文本”的桥梁,我们摒弃了传统的先切割后识别的流水线,采用端到端的先进模型:
- 模型选型: 采用如PaddleOCR、TrOCR或Donut等前沿框架。这些模型通常基于Transformer架构,能够同时处理图像编码和文本解码。
- 关键优势:
- 无需版面分析: Transformer的自注意力机制能全局理解图像上下文,自动学习文档的版面结构(如标题、段落、表格),无需预先进行复杂的版面分割。
- 强大的泛化能力: 对大字体、小字体、艺术字、手写体、表格内容等均有出色的识别效果。
- 位置信息保留: 识别出的每一个文本块(Text Block)都附带其精确的坐标边界框(Bounding Box),这是后续进行结构化抽取的关键。
2.3 基于多模态与预训练模型的合同信息抽取
这是产品的“大脑”,也是技术含量最高的部分。我们在此构建了一个多模态理解管道:
- 2.3.1 实体识别与分类
- 技术核心: 采用在大规模语料上预训练的语言模型(如BERT、RoBERTa、DeBERTa或其领域适配版本如LawBERT)作为编码器。
- 方法: 将OCR输出的文本序列输入模型,通过序列标注任务(如BIEO标注),识别并分类出合同中的关键实体。例如:
- 签署方(PARTY): “甲方:[上海XX科技有限公司]”
- 金额(AMOUNT): “合同总价款为[人民币壹佰万元整](¥[1,000,000.00])”
- 日期(DATE): “本合同自[2023年10月1日]起生效”
- 责任条款(OBLIGATION): “乙方应于[货物交付后15个工作日内]完成验收”
- 2.3.2 多模态特征融合
- 对于某些依赖版式信息的字段(如“合同总价”通常位于文档顶部或底部,签名栏位于末尾),纯文本模型可能失效。我们引入LayoutLMv3或UDOP等多模态预训练模型。这类模型在训练时同时摄入:
- 文本嵌入(Text Embedding)
- 视觉嵌入(Visual Embedding): 来自图像编码器的特征
- 布局嵌入(Layout Embedding): 文本的2D位置坐标
- 通过这种方式,模型能理解“位于文档右下角的一个文本块,其内容是‘法定代表人’,那么它旁边的签名很可能就是签署人实体”,极大地提升了抽取准确率。
- 2.3.3 关系抽取与结构化
- 在识别实体的基础上,进一步抽取实体间的关系,形成结构化数据。例如,将“甲方”、“乙方”、“合同金额”、“生效日期”等实体及其关系,自动填充到预定义的结构化JSON或数据库表中,形成最终的合同信息摘要。
2.4 智能合同比对与分析
这是合同管理产品的另一大核心功能,基于NLP的文本相似度与差异分析技术。
- 技术实现:
- 文本表示: 使用Sentence-BERT或SimCSE等模型,将合同条款转换为高维向量。
- 段落对齐: 基于向量相似度,将待比对的两份合同(如新版本与旧版本)的条款进行智能匹配对齐。
- 差异检测:
- 字符级差异: 类似代码Diff工具,高亮显示增、删、改的词语。
- 语义级差异: 更高级的功能。即使措辞完全不同,但语义相近的条款(如“不可抗力”条款的不同表述)可被标记为“语义无实质变更”;而措辞微小改动但语义发生重大变化的条款(如将“赔偿上限为合同总额的100%”改为“50%”),则被系统高风险标注。
- 风险提示: 结合预设的风险词库和规则,自动识别比对结果中的潜在风险点(如责任加重、付款期限延长、知识产权归属变更等),并生成比对报告。
3. 产品应用场景
基于上述技术,合同OCR智能产品可衍生出多个核心应用:
- 合同『数据中心』: 自动将海量历史合同『数字化』、结构化,形成可查询、可分析的数据资产。
- 智能审核助手: 在合同起草和审核阶段,自动提取关键信息,提示缺失条款、矛盾条款,并关联历史相似合同进行推荐,提升法务和业务人员审核效率50%以上。
- 精准合同比对: 快速定位版本间的差异,聚焦核心变更点,辅助决策,避免人为疏忽。
- 履约与风险监控: 自动提取合同中的关键日期(如付款、验收、到期日)和义务条款,接入工作流系统,实现自动提醒和风险预警。
4. 挑战与未来展望
尽管技术已取得长足进步,但挑战依然存在:(1)对极其复杂、潦草手写体的识别;(2)对高度隐含和依赖上下文的语义理解(如某些附条件的义务);(3)模型的可解释性。未来,我们将重点关注:
- 『大语言模型』的深度融合: 利用ChatGPT、GLM等千亿级模型的强大推理和生成能力,实现更复杂的合同问答、条款改写和摘要生成。
- 持续学习与领域自适应: 让模型能够在实际业务流中持续学习新的合同类型和法规,不断进化。
- 可信AI与合规性: 确保模型决策过程透明、公正,并符合日益严格的数据安全与隐私法规。
5. 结论
本文从产品视角详细论证了构建一个现代化合同OCR智能处理系统的可行性与技术路径。通过深度融合基于深度学习的OCR技术与先进的NLP模型,特别是多模态预训练模型的应用,我们能够超越单纯的文字识别,实现对合同文档的深度语义理解与结构化信息抽取。由此催生的合同提取、智能比对等核心产品功能,正在深刻地变革企业的合同管理模式,将其从被动、低效的文件保管,转向主动、智能的数据驱动决策,最终为企业的合规风控和运营效率带来质的飞跃。



