(来源:机器之心)
本研究由解放军总医院牵头,联合浙江大学医学院附属第二医院、复旦大学附属华山医院等共 11 家国内顶尖三甲医院,携手南京大学、吉林大学两所重点高校,并汇聚 Pi3Lab、上海三友医疗器械股份有限公司等产学研多方力量,共同完成了首个面向脊柱诊疗领域的大模型研发。
论文共同第一作者包括赵明、董文辉博士、张阳医生,核心贡献者包括来自浙江大学医学院附属第二医院的陈其昕教授、夏顺楷医生,以及复旦大学附属华山医院的马晓生教授、管韵致医生等。通讯作者为解放军总医院骨科医学部副主任孙天胜教授,共同通讯作者为南京大学智能科学与技术副院长单彩峰教授。
脊柱疾病影响全球 6.19 亿人,是致残的主要原因之一 。然而,现有 AI 模型在临床决策中仍存在「认知鸿沟」。缺乏椎体级别(level-aware)、多模态融合的指令数据和标准化基准,是制约 AI 辅助诊断的关键瓶颈。
本文提出了一套统性的解决方案,包括首个大规模、具有可追溯性的脊柱指令数据集 SpineMed-450K,以及临床级评测基准 SpineBench。基于此训练出的专科大模型 SpineGPT,在所有任务上均实现了显著提升,仅仅 7B 参数量,全面超越了包括 GLM-4.5V 和 Qwen2.5-VL-72B 在内的顶尖开源大模型 。
论文地址:https://arxiv.org/pdf/2510.03160
论文地址:https://arxiv.org/pdf/2510.03160
临床痛点:通用 LVLM 的「认知鸿沟」
脊柱疾病的临床诊疗,需要复杂的推理过程:整合 X 光、CT、MRI 等多模态影像的发现,并将病灶精确定位到特定的椎体层面(Level-Aware Reasoning),以确定严重程度并规划干预措施 。这种集成推理能力,是现有通用视觉 - 语言大模型(LVLMs)的系统性弱点 。
在 SpineBench 的评测中,这一弱点暴露无遗 :
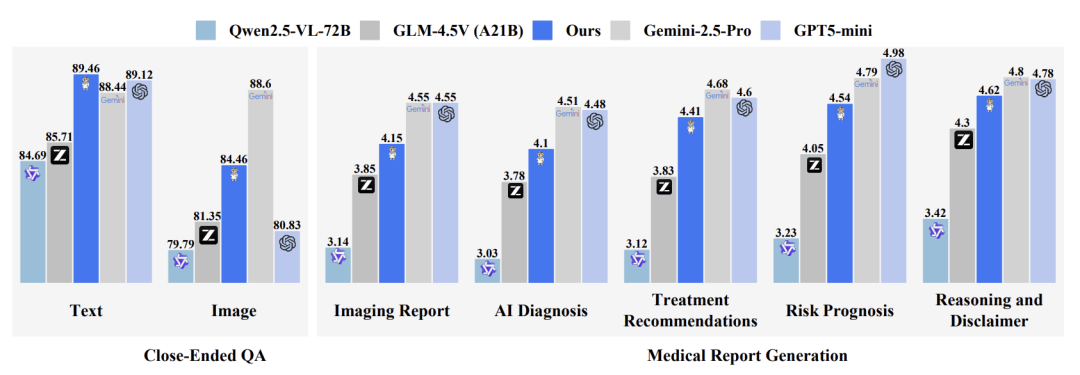
性能差距明显: 即使是参数量达 72B 的 Qwen2.5-VL-72B,平均性能也仅为 79.88%。领先的开源模型 GLM-4.5V (83.26%) 与顶尖专有模型 Gemini-2.5-Pro (89.23%) 之间仍存在近 6 个百分点的差距。在医疗报告生成任务中,更是差距明显,Qwen2.5VL-72B 和 Gemini-2.5-pro 差 30%。
跨模态对齐缺陷: 几乎所有模型在多模态任务上的性能都有不同程度的下降 。例如,GPT5 在纯文本 QA (87.41%) 与图像 QA (79.97%) 之间的差距高达 7.44 个百分点 。这反映了现有模型在医学图像理解和视觉 - 语言对齐上的根本不足,限制了它们在需要综合分析图像和文本的临床场景中的应用。
性能差距明显: 即使是参数量达 72B 的 Qwen2.5-VL-72B,平均性能也仅为 79.88%。领先的开源模型 GLM-4.5V (83.26%) 与顶尖专有模型 Gemini-2.5-Pro (89.23%) 之间仍存在近 6 个百分点的差距。在医疗报告生成任务中,更是差距明显,Qwen2.5VL-72B 和 Gemini-2.5-pro 差 30%。
跨模态对齐缺陷: 几乎所有模型在多模态任务上的性能都有不同程度的下降 。例如,GPT5 在纯文本 QA (87.41%) 与图像 QA (79.97%) 之间的差距高达 7.44 个百分点 。这反映了现有模型在医学图像理解和视觉 - 语言对齐上的根本不足,限制了它们在需要综合分析图像和文本的临床场景中的应用。
核心成果:构建临床级 AI 的「基础设施」
为填补现有数据与临床需求之间的认知鸿沟,研究团队与实践中的脊柱外科医生共同设计和构建了 SpineMed 生态系统。
1. SpineMed-450K:椎体级、多模态指令数据集
这是首个明确为椎体级推理而设计的大规模数据集。

规模与来源: 包含超过 450,000 条指令实例。数据来源极其丰富,包括教科书、外科指南、专家共识、开放数据集(如 Spark、VerSe 20262020),以及约 1,000 例去识别化的多模态医院真实病例。真实病例来源于国内 11 家知名医院,确保了患者来源的多样性 。
生成管线: 数据生成采用了严谨的「临床医生介入」(Clinician-in-the-loop)流程。该流程涉及:
规模与来源: 包含超过 450,000 条指令实例。数据来源极其丰富,包括教科书、外科指南、专家共识、开放数据集(如 Spark、VerSe 20262020),以及约 1,000 例去识别化的多模态医院真实病例。真实病例来源于国内 11 家知名医院,确保了患者来源的多样性 。
生成管线: 数据生成采用了严谨的「临床医生介入」(Clinician-in-the-loop)流程。该流程涉及:
——使用 PaddleOCR 提取图文信息;
——通过新型的图像 - 上下文匹配算法,将图像与其周围的文本上下文精确绑定,保证可追溯性;
——利用 LLM 两阶段生成方法(起草和修订)来生成高质量的指令数据,且临床医生参与了提示词策略和修订标准的审查。
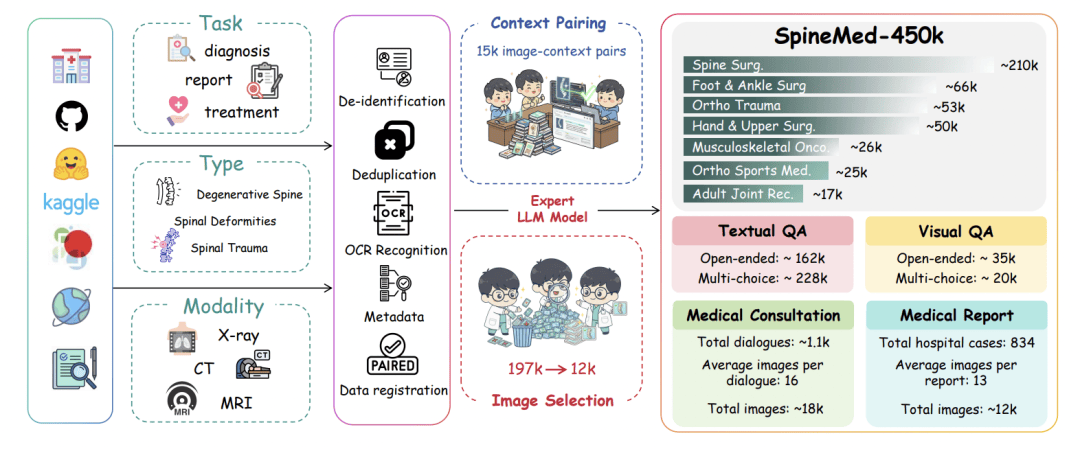
任务多样性: 涵盖四种类型——多项选择 QA(249k)、开放式 QA(197k)、多轮诊疗对话(1.1k)和临床报告生成(821 例)。数据覆盖七个骨科亚专科,其中脊柱外科数据占比 47%,并细分为 14 种脊柱亚疾病。
任务多样性: 涵盖四种类型——多项选择 QA(249k)、开放式 QA(197k)、多轮诊疗对话(1.1k)和临床报告生成(821 例)。数据覆盖七个骨科亚专科,其中脊柱外科数据占比 47%,并细分为 14 种脊柱亚疾病。
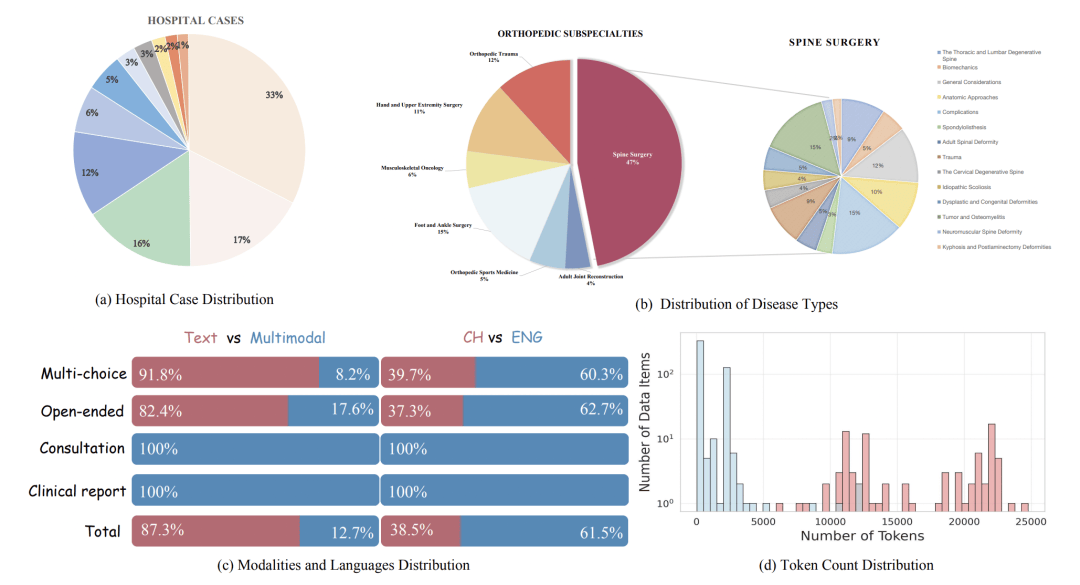
2. SpineBench:首个临床显著性评估基准
SpineBench 是一个与临床深度结合的评估框架,旨在评估 AI 在细粒度、以解剖为中心的推理中犯下的、在实践中至关重要的错误类型。
基准构成: 最终包含 487 道高质量多项选择题和 87 个报告生成提示 。
严谨验证: 为确保评估集的完整性,由 17 名骨科外科医生组成的团队,分成三个独立小组进行了严格的验证和校正。
报告评估:针对临床报告生成任务,设计了由专家校准的框架。评估从五大板块、十个维度进行:
基准构成: 最终包含 487 道高质量多项选择题和 87 个报告生成提示 。
严谨验证: 为确保评估集的完整性,由 17 名骨科外科医生组成的团队,分成三个独立小组进行了严格的验证和校正。
报告评估:针对临床报告生成任务,设计了由专家校准的框架。评估从五大板块、十个维度进行:
结构化影像报告(SIP):评估发现的准确性、临床意义和定量描述 。
AI 辅助诊断(AAD):评估主要诊断的正确性、鉴别诊断和临床推理 。
治疗建议(TR):分为患者指导(语言清晰度、共情、安抚)、循证计划(理由、指南一致性)和技术可行性(手术细节、并发症预防)。
风险与预后评估(RPM):评估围手术期管理、随访安排和潜在问题策略 。
推理与免责声明(RD):评估证据覆盖范围、相关性、细节粒度和逻辑连贯性。
结构化影像报告(SIP):评估发现的准确性、临床意义和定量描述 。
AI 辅助诊断(AAD):评估主要诊断的正确性、鉴别诊断和临床推理 。
治疗建议(TR):分为患者指导(语言清晰度、共情、安抚)、循证计划(理由、指南一致性)和技术可行性(手术细节、并发症预防)。
风险与预后评估(RPM):评估围手术期管理、随访安排和潜在问题策略 。
推理与免责声明(RD):评估证据覆盖范围、相关性、细节粒度和逻辑连贯性。
实验结果:专科 AI 模型 SpineGPT 的突破性表现
SpineGPT 基于 Qwen2.5-VL-7B-Instruct 模型,通过课程学习(Curriculum Learning)框架,分三阶段在 SpineMed-450K 上进行微调,以逐步增强其在脊柱健康领域的适用性和专业性 。
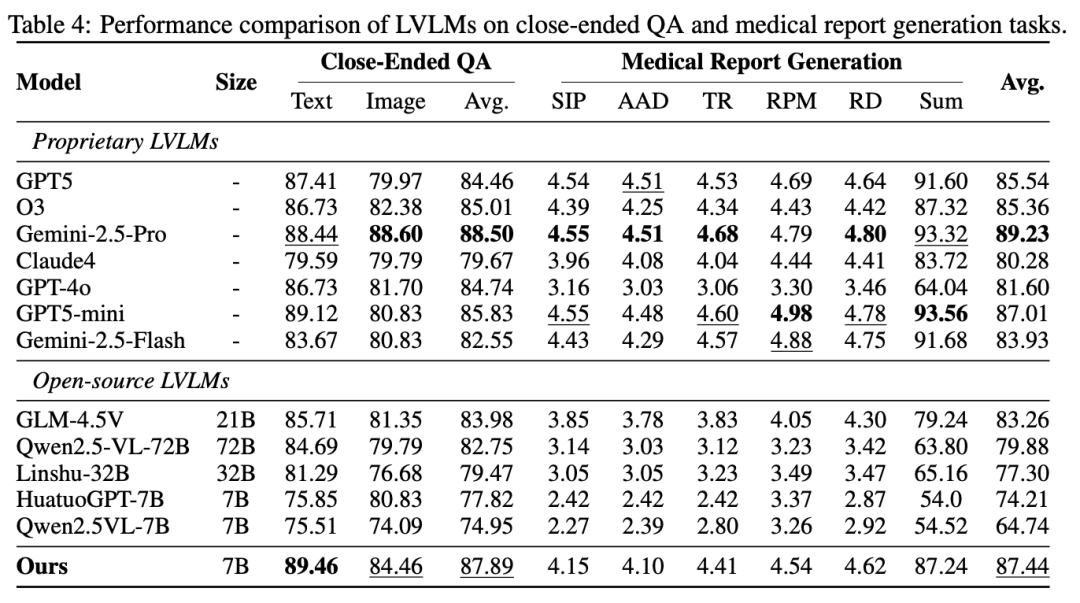
1.超越开源,逼近顶尖专有模型: SpineGPT 达到了 87.44% 的平均分,大幅领先所有开源大模型 4.18 个百分点以上。在纯文本 QA 任务上(89.46%),SpineGPT 甚至超越了所有参评模型,包括 GPT5 (87.41%) 。
2.专科数据的重要性(消融实验):
模型仅在通用医疗数据上训练时,性能显著下降(74.95% vs 65.31%)。
纳入精心策划的非脊柱通用骨科数据后,性能得到大幅提升(82.14% vs 74.95%),验证了领域对齐训练数据的重要性。
最终,纳入脊柱特异性训练数据(包括对话、报告生成和长链推理指令)后,模型性能进一步增强至 87.89%。
模型仅在通用医疗数据上训练时,性能显著下降(74.95% vs 65.31%)。
纳入精心策划的非脊柱通用骨科数据后,性能得到大幅提升(82.14% vs 74.95%),验证了领域对齐训练数据的重要性。
最终,纳入脊柱特异性训练数据(包括对话、报告生成和长链推理指令)后,模型性能进一步增强至 87.89%。
3.临床报告能力显著增强: SpineGPT 在医疗报告生成任务上的总分为 87.24 分,而 Qwen2.5-VL-72B 仅为 63.80 分,ChatGPT-4o 为 64.04 分。
案例对比:在对「青少年特发性脊柱侧凸」病例的分析中,SpineGPT 提供了包含 72 个详细的临床处理流程,涵盖了完整的影像发现、AI 诊断、患者和医生导向的治疗建议、风险管理和术后问题管理。相比之下,ChatGPT-4o 的报告则更偏向『于适』合一般医疗文档的基本诊断和治疗建议。
案例对比:在对「青少年特发性脊柱侧凸」病例的分析中,SpineGPT 提供了包含 72 个详细的临床处理流程,涵盖了完整的影像发现、AI 诊断、患者和医生导向的治疗建议、风险管理和术后问题管理。相比之下,ChatGPT-4o 的报告则更偏向『于适』合一般医疗文档的基本诊断和治疗建议。

4.人类专家高度认可: 人类专家对报告评分与 LLM 自动评分之间的 Pearson 相关系数达到 0.382 至 0.949,大多数维度相关性在 0.7 以上。这有力地验证了 LLM 自动评分作为专家判断代理的可靠性。
结论与展望
这项研究证明了:对于脊柱诊断这样需要复杂解剖推理的专业领域,专科指令数据和「临床医生介入」的开发流程是实现临床级 AI 能力的关键。
SpineMed-450K 和 SpineBench 的发布,为未来的 AI 研究提供了一个高实用性的基线。研究团队计划将拓展数据集、训练大于 7B 参数的模型,并结合强化学习技术,继续深化与领先专有模型的直接比较,以确立更清晰的性能基准。
Pi3Lab 介绍
Pi3Lab 专注于 AI Agent 的行业落地,致力于通过 RLaaS 平台让通用模型在实际业务中真正低成本、高效率地用起来。目前我们正在招聘 RL RA(强化学习研究助理),欢迎投递简历:wenhui.dong@pi3lab.com




