新加坡国立大学和Lowart AI发布OmniPSD。

利用Diffusion Transformer架构解决了分层图像生成与拆解的难题,实现了真正可编辑的PSD文件输出。
这是AI从生成图片向生成资产跨越。
OmniPSD能通过文本生成带有透明通道的分层PSD文件,还能将单张平面图像逆向拆解为可编辑的图层结构,解决了AI生成图像难以二次编辑的痛点。
平面图像生成的局限与分层结构的刚需
以Stable Diffusion和Midjourney为代表的生成式模型彻底改变了图像创作的门槛,只需一段文字,精美的画面便跃然屏上。
这些模型生成的图像在本质上是一张死图——即扁平化的光栅图像(Raster Image)。
对于专业『设计师』而言,这种格式虽然美观,却缺乏实际应用中最关键的属性:结构化。
在现代数字内容创作(DCC)的工作流中,Adobe Photoshop的PSD格式之所以成为行业标准,是因为它保留了图层(Layers)、透明度(Alpha Channel)和合成关系。
『设计师』需要独立的背景层、前景主体层和可编辑的文本层,以便进行移动、缩放、替换或二次排版。
目前的生成模型产出的JPEG或PNG图像,一旦生成,像素便粘在了一起,想要修改其中一个元素,往往需要借助复杂的掩膜(Masking)或重绘(Inpainting)手段,且效果难以保证完美。
为了填补这一鸿沟,新加坡国立大学与Lovart AI的研究团队推出了OmniPSD。
这是一个建立在Flux生态系统之上的统一框架,它在一个模型架构内同时实现了两个核心功能:Text-to-PSD(文本到PSD生成)和Image-to-PSD(图像到PSD拆解)。
jrhz.info这不仅仅是图像分割,而是生成具有透明通道、边缘清晰、且保留了设计语义的独立图层。
在分层生成任务中,最棘手的技术挑战之一是如何处理透明度。
标准的图像生成模型通常在RGB色彩空间中工作,而忽略了Alpha通道(透明度信息)。
传统的变分自编码器(VAE)在压缩和解压图像时,往往无法准确保留半透明区域(如玻璃、烟雾、头发边缘)的细节,导致解压后的图层边缘出现锯齿或白边。
OmniPSD的核心组件是一个经过重新训练的RGBA-VAE。
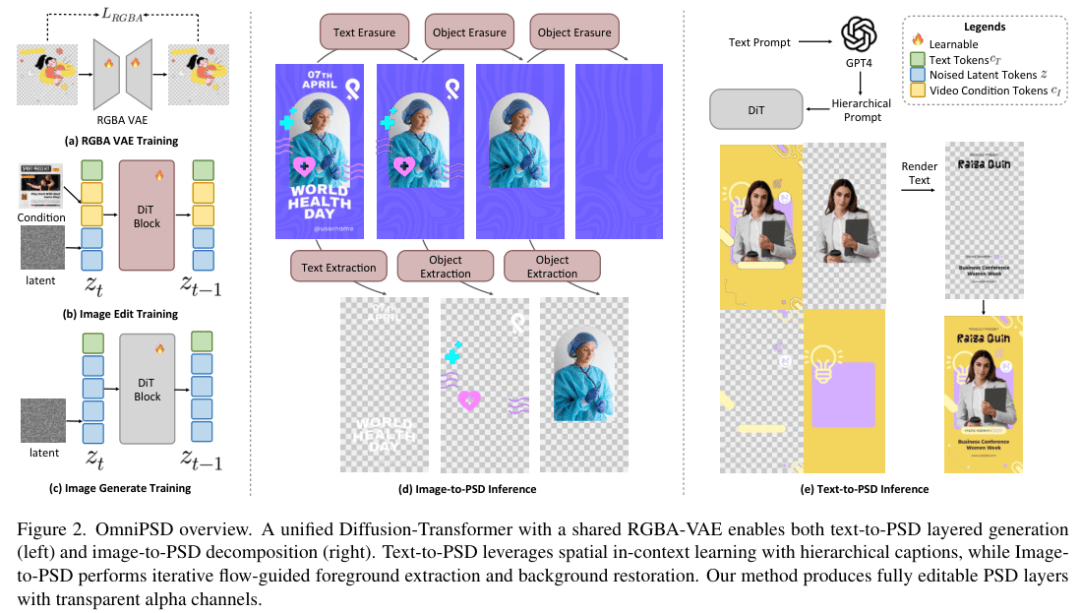
研究团队并没有直接使用Flux模型自带的VAE,因为原版VAE是在自然图像上训练的,对透明背景的理解有限。
团队构建了一个包含大量具有透明背景的合成数据和真实设计素材的数据集,专门用于训练这个能够感知Alpha通道的编码器。
这个RGBA-VAE的设计目标是将带有透明度的图像压缩到一个潜在空间(Latent Space)中,同时不丢失结构信息。
为了实现这一点,训练过程引入了多种损失函数:像素级的L1损失用于保证色彩还原,Patch级的特征损失用于保持局部结构,感知损失(Perceptual Loss)用于维持语义一致性,以及KL散度用于规范化潜在空间的分布。
通过这种方式,RGBA-VAE成为了连接像素空间与潜在空间的桥梁。
无论是生成的图层,还是从原图中拆解出的图层,都能通过这个模块获得高质量的透明通道信息。这使得生成的图层不再是简单的抠图,而是包含了半透明过渡、光影投射等丰富细节的完整资产。
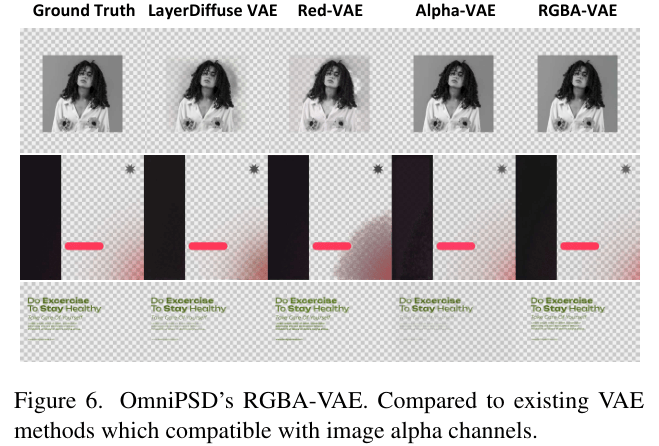
在上图中可以看到,相比于LayerDiffuse VAE、Red-VAE和Alpha-VAE,OmniPSD所使用的RGBA-VAE在重建透明图像时,保留了更多的细节和更准确的透明度过渡,避免了边缘的模糊和伪影。
基于Flux架构的统一生成与拆解流程
OmniPSD并没有从零开始训练一个巨大的扩散模型,而是巧妙地站在了巨人的肩膀上——Flux生态系统。
Flux是目前先进的开源Diffusion Transformer(DiT)模型之一,拥有强大的文本理解能力和图像生成质量。
OmniPSD针对生成和拆解两个不同的任务,分别利用了Flux-dev和Flux-Kontext两个变体,并通过LoRA(Low-Rank Adaptation)技术进行了高效的微调。
这种架构设计的精妙之处在于上下文学习(In-Context Learning)。
传统的图像生成模型一次只能生成一张图,或者需要通过复杂的控制网(ControlNet)来引导布局。OmniPSD创新性地采用了网格化(Grid)的策略,将多个图层视为同一张大图的不同部分进行联合生成。
在Text-to-PSD任务中,模型将输出画布划分为一个2x2的网格。
左上角是完整的合成海报,右上角是前景层,左下角是中景层,右下角是背景层。
这种空间排列让Transformer模型中的注意力机制(Attention Mechanism)能够同时看到整体和局部。
当模型生成前景层时,它可以通过注意力机制参考完整海报的布局,从而确保前景物体的位置、光影与整体环境协调一致。
这种方法不需要引入额外的跨层注意力模块,仅利用DiT原本强大的全局注意力能力,就实现了图层间的语义对齐。
对于Image-to-PSD的拆解任务,逻辑则完全相反但思路相通。这是一个逆向工程的过程。给定一张平面的海报图像,模型需要将其分解为独立的文本、前景和背景。这里利用了Flux-Kontext模型的图像编辑能力。
拆解过程被设计为一个迭代的流水线:
文字提取与擦除:首先识别并提取图像中的文字层,然后利用修补(Inpainting)技术将文字覆盖的区域擦除,还原出无文字的背景。
前景提取与背景修复:在无文字图像的基础上,模型进一步识别前景主体,将其提取为带透明通道的图层,然后再次利用修补技术,猜测被前景遮挡的背景内容,最终生成一张干净、完整的背景图。
这一过程不仅依赖于图像分割,更依赖于生成模型的联想能力。当一个人物从背景中被移走后,模型需要脑补出人物背后的墙壁、风景或纹理。Flux强大的生成底座保证了这种脑补的合理性和真实感。
数据集的构建与层级化训练
AI模型的性能很大程度上取决于数据的质量。
现有的公开数据集虽然庞大,但大多是扁平的RGB图像,缺乏高质量的分层信息。
为了训练OmniPSD,研究团队构建了一个名为Layered Poster Dataset的大规模数据集,包含超过20万个真实的PSD文件。
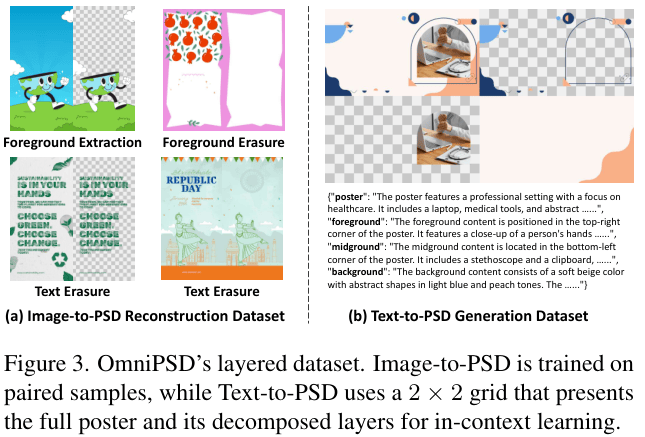
这些PSD文件均由专业『设计师』制作,包含了丰富的图层结构、复杂的遮挡关系和多样的设计风格。
为了让模型能够理解这些数据,团队对原始文件进行了细致的清洗和解析。
他们提取了文本、前景和背景的元数据,包括边界框(Bounding Box)、层级顺序和可视性信息。
针对Text-to-PSD任务,数据被处理成上述的2x2网格格式,并配以层级化的文本描述(Hierarchical Captioning)。
这种描述不仅仅是一句简单的Prompt,而是一个JSON格式的结构化数据,分别描述了整张海报的主题、前景的具体内容、中景的元素以及背景的纹理。
这迫使模型在生成时必须具备极强的语义对应能力,不能张冠李戴。
针对Image-to-PSD任务,数据则被组织成三元组(Triplet):原始图像、提取出的前景、移除前景后的背景。
这种数据结构模拟了『设计师』手动修图的过程,让模型学会如何从整体中剥离局部,并修复留下的空洞。

为了验证OmniPSD的效果,研究团队进行了广泛的定量和定性实验。
在Text-to-PSD任务中,OmniPSD与LayerDiffuse和GPT-Image-1等现有最先进的方法进行了对比。
评估指标包括FID(Fréchet Inception Distance,用于衡量图像真实感)和CLIP Score(用于衡量图文一致性)。
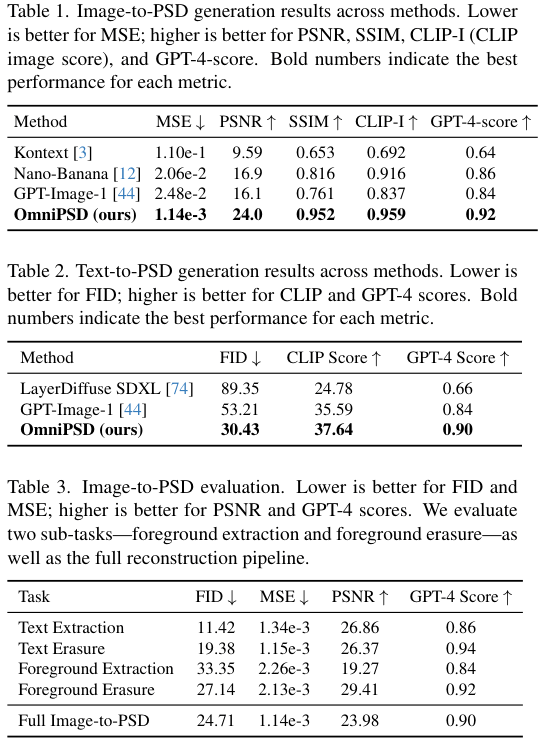
结果显示,OmniPSD在各项指标上均取得了显著优势。
特别是在生成带有复杂透明度效果的图层(如半透明的纱裙、发光的特效)时,OmniPSD展现出了惊人的细节表现力,而对比模型往往只能生成生硬的边缘。
在Image-to-PSD任务中,由于这是一个全新的任务设定(即从单张图直接重构出完整的PSD结构,包括被遮挡的背景),目前市场上缺乏完全对标的竞品。
团队设置了几个强有力的基线模型,包括基于SAM2(Segment Anything Model 2)的分割方案。
实验表明,仅靠分割模型(SAM2)无法恢复被遮挡的背景区域,得到的只是一个个补丁;而OmniPSD不仅精准提取了前景,还完美重绘了背景,使得拆解后的图层可以随意移动而不会露出破绽。

对比图中可以清晰地看到,其他方案在处理复杂边缘和背景一致性上存在明显缺陷,例如LayerDiffuse生成的背景往往包含前景的残影,或者结构混乱,而OmniPSD生成的各个图层不仅清晰,而且组合在一起时天衣无缝。
对于『设计师』而言,能够直接生成可编辑的源文件,意味着AI不再只是灵感参考工具,而是真正进入了生产管线。
这种技术有潜力改变广告设计、游戏美术UI制作以及电商海报生成的流程。
『设计师』可以先用Image-to-PSD功能拆解已有的素材,快速替换背景或调整构图,或者直接用Text-to-PSD功能生成一套基础素材,再在此基础上进行精细化调整。
未来的图像生成,必然是结构化、语义化且高度可控的。
当AI开始懂得图层的逻辑,设计的边界将被无限拓宽。
参考资料:
https://arxiv.org/abs/2512.09247
https://showlab.github.io/OmniPSD/
END




