一、 合同提取的逻辑本质:从视觉符号到法律语义的多层级解码
OCR合同提取的逻辑绝非简单的“扫描-识别-归档”,而是一个融合几何感知、语义理解、逻辑推理与合规审查的复杂认知过程。其核心目标是将非结构化的合同文档图像,转化为机器可读、可查询、可分析的结构化知识网络,同时确保这一转化过程的法律严谨性与业务实用性。这一过程需破解三重核心逻辑挑战:
- 结构与内容的双重复杂性:合同是高度结构化的法律文件,但具体表现形式(版式、模板)千变万化。它混合了条款文本(非结构化)、关键信息字段(半结构化)、签章区域(视觉要素)及修订痕迹。系统必须同时理解“这份文档是合同”的宏观体裁,以及“某条款属于保密协议”的微观语义。
- 专业术语与长程依赖:法律语言精确且包含大量专业术语(如“不可抗力”、“瑕疵担保”)。关键信息(如“违约责任”中的赔偿金额)往往依赖于上下文多处表述(如定义条款、附件)才能被完整、正确地理解。
- 高精度与可解释性要求:一个字符的误识别(如将“10%”误为“1%”)或条款的误分类,都可能导致法律风险。系统不仅需要输出结果,更需要对“为何如此提取”提供可追溯的依据,以满足法务审查的合规要求。
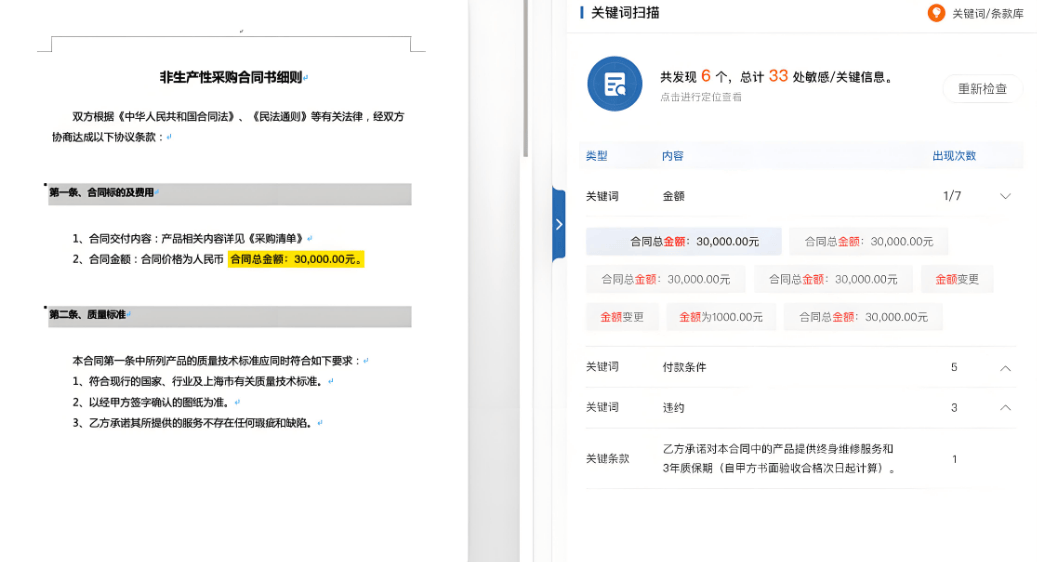 合同OCR提取识别
合同OCR提取识别
因此,一个完整的合同OCR提取系统遵循以下三层递进的逻辑链:
第一层:多模态文档理解与细粒度信息定位
- 逻辑:系统首先将合同图像视为一个由文本、布局、印章、签名构成的整体。利用文档视觉-语言预训练模型,同时分析文本内容和二维空间布局关系,识别出文档标题、章节标题、段落、表格、签署区等逻辑区块。这一步骤的关键在于,它不仅“看到了”文字,还理解了“甲方”、“乙方”等字段名称与其对应值的空间关联关系(通常是左右或上下邻近)。
第二层:法律语义解析与实体关系抽取
- 逻辑:在定位的基础上,系统进行深度的语义分析。这通常是一个命名实体识别与关系抽取的联合任务,由领域知识增强的自然语言处理模型完成。
- 实体识别:精准抽取出法律实体,如“合同双方”(公司全称、法定代表人)、“关键日期”(生效日、履行期限)、“金额与支付条款”、“违约责任”、“管辖法院”等。这要求模型在法律文本语料上经过充分训练。
- 关系抽取与关联:建立实体间的逻辑联系。例如,将“赔偿金额:人民币壹佰万元”与“若乙方未能按期交付……”这一违约情形关联起来;将附件列表中的文件名与正文中的引用点进行关联。
第三层:业务规则校验与风险要素结构化
- 逻辑:这是从“信息提取”升维至“知识创造”的一步。系统内嵌或可配置行业及公司特定的合同审查规则库。
- 逻辑一致性校验:自动检查合同中是否存在矛盾条款(如不同条款中的付款比例之和是否超过100%)、关键信息缺失(如未约定争议解决方式)。
- 风险条款识别与标签化:基于规则或机器学习模型,自动识别出高风险、非标准或对公司不利的条款(如过于宽泛的保密义务、不明确的验收标准),并打上风险标签,生成审查要点提示。
- 知识图谱构建:最终输出不是一个孤立的字段列表,而是一个包含“主体-义务-权利-时间-金额-违约”等节点和关系的轻量级合同知识图谱,为后续的审阅、分析、比对和归档提供结构化基础。
二、 智能合同OCR提取产品的核心能力架构
一款成熟的企业级合同提取产品,应围绕 “精准、智能、安全、开放” 构建一个完整的解决方案平台。
1. 自适应多版式解析引擎
- 技术核心:产品内置强大的多模态预训练模型作为基座。该模型在海量法律文档、商业合同上训练,能适应不同律所、不同行业、不同国家的千变万化的合同模板,实现“开箱即用”。对于企业自有模板,系统支持通过少量样本(3-5份)进行快速微调,达到接近100%的关键字段提取精度。
- 复杂元素处理:能够精确处理合同中常见的骑缝章、手写签名、修订批注(如“云线”)、附件及扫描件瑕疵,确保信息提取的完整性和准确性。
2. 领域知识增强的语义理解中枢
- 法律与行业知识库:产品集成或可方便地接入法律术语库、标准条款库、企业历史合同库。这使得模型不仅能识别文字,更能理解条款的业务意图和法律后果。
- 智能条款分类与摘要:自动将冗长的合同条款归类到预设的类别体系(如付款、交付、知识产权、保密、终止等),并可生成条款内容的简明摘要,极大提升法务和业务人员的审阅效率。
- 上下文关联理解:具备跨页、跨章节的关联能力。例如,能理解“如附件一所述”并自动关联到附件内容;能将正文中的“质量标准”与附件中的技术参数表联系起来。
3. 风险洞察与自动化审查工作流
- 合规规则引擎:提供可视化或脚本化的规则配置界面,允许企业法务部门将内部合规要求(如“所有对外付款合同必须经财务总监审批”)和风险偏好(如“违约责任上限不得超过合同总额的20%”)固化为自动化审查规则。
- 风险评分与亮点报告:对每份提取后的合同,自动生成一份风险审查快报,高亮关键风险点、缺失项、与非标准条款,并给出一个总体风险评分,辅助法务人员确定审查优先级。
- 智能比对与版本管理:自动比对合同初稿与终稿、本方模板与对方来稿的差异,精确到词语级别,并标记语义变化(如“可以”变为“应当”),支持高效的谈判和版本追溯。
4. 企业级部署与生态集成能力
- 全栈安全与私有化:鉴于合同的敏感性,产品必须支持全栈私有化部署,所有数据处理均在客户内网完成。系统需具备完整的操作审计日志,满足数据主权和合规要求。
- 开放的API与生态连接:提供标准、稳定的API,使其提取出的结构化合同数据,能够无缝流入企业的合同生命周期管理系统、ERP、CRM、电子签章平台或财务系统,真正实现从“文档”到“数据”再到“业务流程”的自动化驱动。
三、 市场应用前景与产品演进方向
合同智能化管理是企业合规与运营『数字化』的核心战场,相关OCR提取产品市场前景广阔。
- 核心应用场景:
- 大型企业法务与采购部门:自动化处理海量采购、销售、NDA等合同,实现从起草、审批、签署到归档的全生命周期『数字化』管理。
- 金融机构风控与合规:在信贷、投融资业务中,快速解析贷款协议、投资协议,自动核验关键条款,进行风险筛查。
- 律师事务所与审计机构:辅助律师进行尽职调查,批量分析目标公司历史合同,提取风险点;帮助审计师进行合同合规性审计。
- 未来演进方向:
- 与生成式AI的深度结合:未来系统不仅能“读”合同,更能“写”和“改”合同。基于提取的结构化知识,自动生成合同摘要、审查意见,甚至根据谈判结果起草修订建议。
- 预测性分析与决策支持:基于历史合同履行数据(如付款延期、纠纷发生情况),结合当前合同条款,预测潜在履约风险,为商业决策提供数据支持。
- 跨合同知识网络与洞察:在企业层面,将散落在各处的合同连接起来,构建企业级的履约义务与权利图谱,洞察供应商/客户集中度、知识产权布局等战略信息。
四、 优秀产品的关键选型维度
jrhz.info企业在选型时,应进行多维度、场景化的深度评估:
- 语义理解精度与专业度验证:准备一个包含复杂权利义务条款、多方签署页、详细附件的真实合同测试集。核心考察产品对“违约金计算方式”、“知识产权归属”、“争议解决机制”等复杂长句的语义抽取是否准确、完整。
- 规则配置灵活性与业务贴合度:测试其规则引擎是否强大且易用。能否方便地将企业内部复杂的法务审查清单(如“确保我方拥有单方面解除权”)配置为自动化规则?这是产品能否“活”起来、适应企业个性化需求的关键。
- 安全合规性的“一票否决”:彻底审查其数据安全架构、私有化部署方案、审计日志机制。确保其满足企业信息安全最高等级要求,并符合相关法律法规。
- 系统集成与总拥有成本:评估其与企业现有系统集成的难度、API的成熟度。计算总拥有成本时,不仅要考虑软件许可费,更要考虑因流程效率提升、风险降低带来的业务价值回报。
结论
智能合同OCR提取系统,标志着法律文档处理从“文档管理”进入了“知识管理与风险治理”的新时代。它通过将深度学习的感知能力、自然语言处理的语义理解能力与企业法务的领域知识深度融合,将静态的、封闭的合同文本,转化为动态的、可计算的、可关联的战略数据资产。
选择并成功部署这样一款产品,意味着企业不仅在合同处理效率上实现了数量级的提升,更在风险管控、合规运营和商业洞察方面构建了全新的『数字化』能力。它不再是一个简单的效率工具,而是企业法务部门乃至整个组织,在日益复杂的商业和法律环境中,实现精细化管理和战略性决策的核心认知基础设施。




