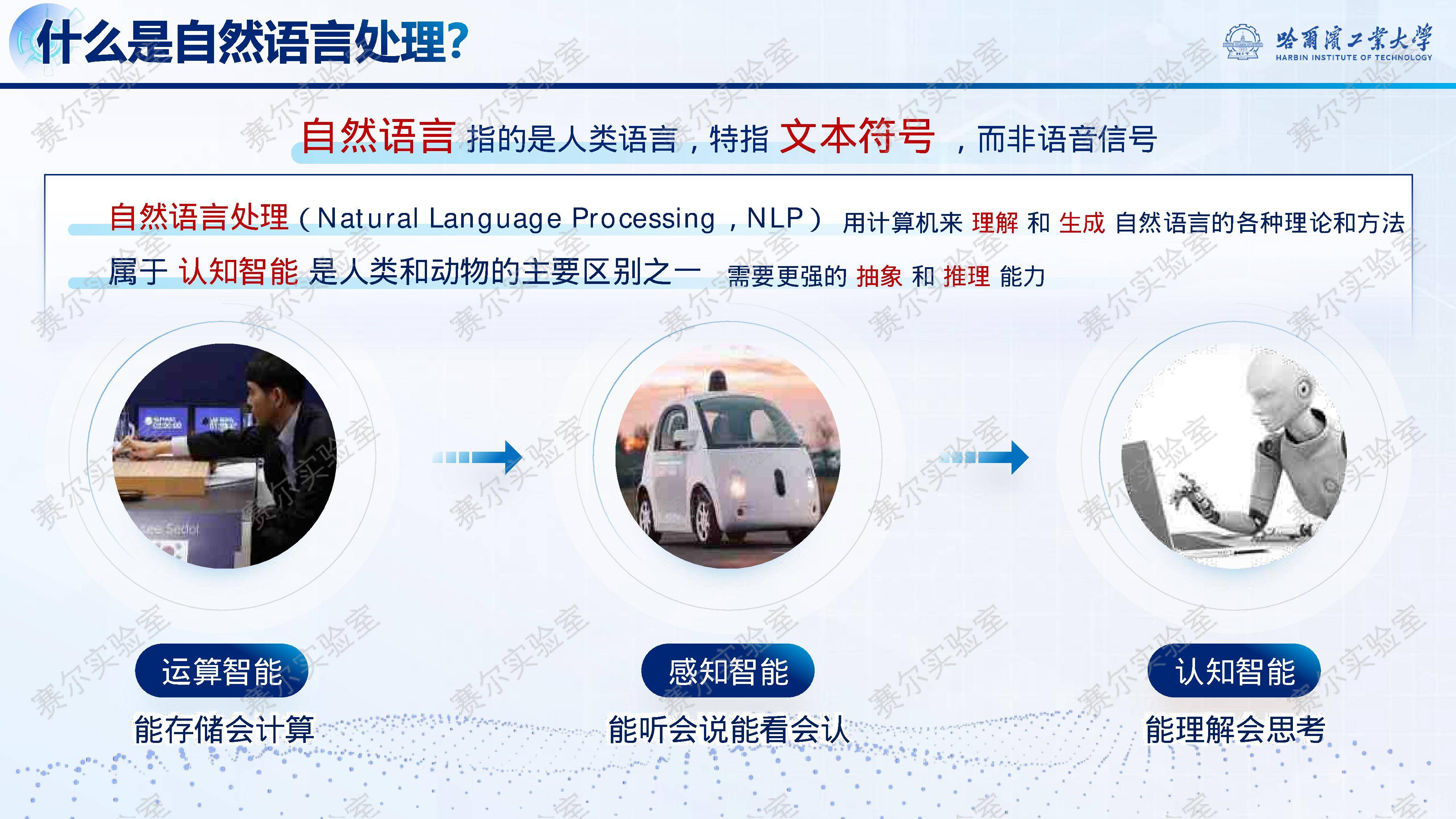
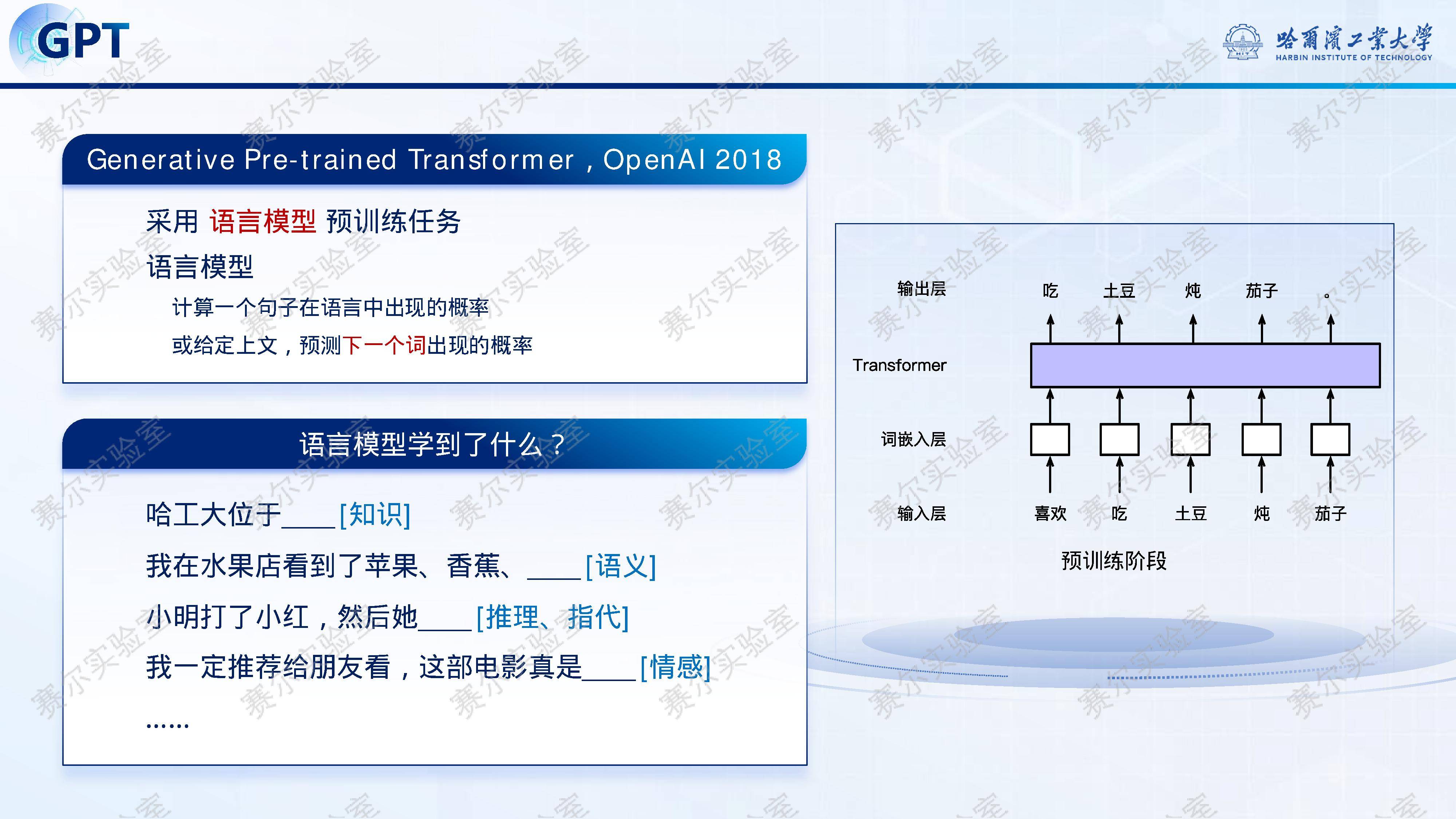
近年来,自然语言处理(NLP)作为“人工智能皇冠上的明珠”,经历了从专家系统、浅层机器学习到深度学习、预训练语言模型的五次范式变迁。2025年,以『DeepSeek』-R1为代表的大模型标志着第六次范式跃迁——推理能力的系统性突破。报告指出,『大语言模型』之所以成为AI基石,在于语言承载了人类绝大部分知识,是认知智能的核心载体。然而,早期如GPT-3虽具规模优势,却在知识推理、可解释性与鲁棒性方面存在明显短板,难以真正理解深层语义。
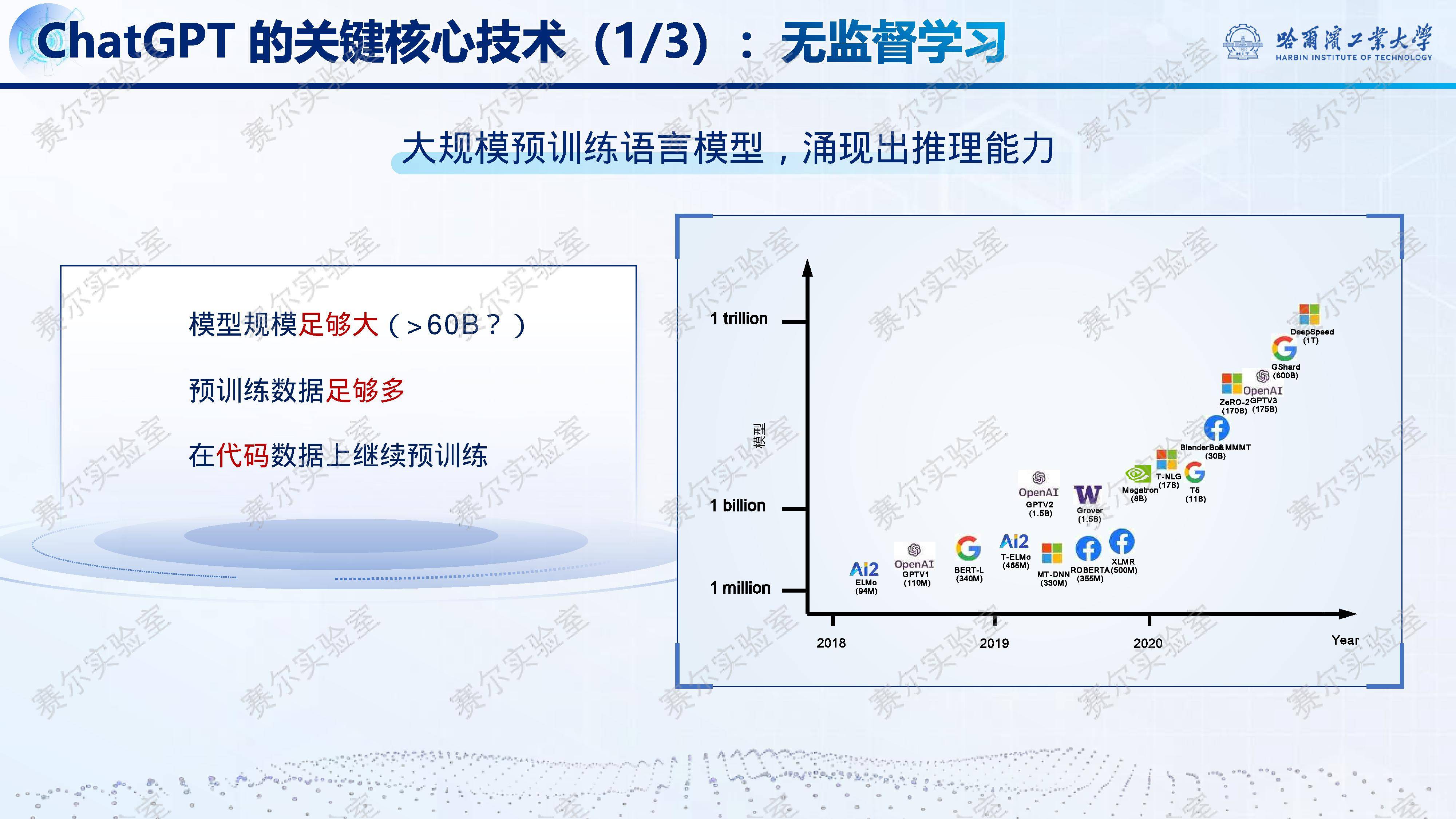
为攻克这一瓶颈,『DeepSeek』系列模型通过创新技术路径实现飞跃。『DeepSeek』-R1-Zero首次仅凭强化学习(RL)便让模型自主习得复杂推理能力,无需监督微调,其AIME 2024竞赛pass@1分数从39.2%跃升至71.0%,逼近OpenAI o1水平。更关键的是,研究发现简单的GRPO算法配合结果奖励即可高效驱动推理能力涌现,并伴随“反思机制”的自发形成与思维链长度的自然增长,揭示了RL在认知建模中的巨大潜力。
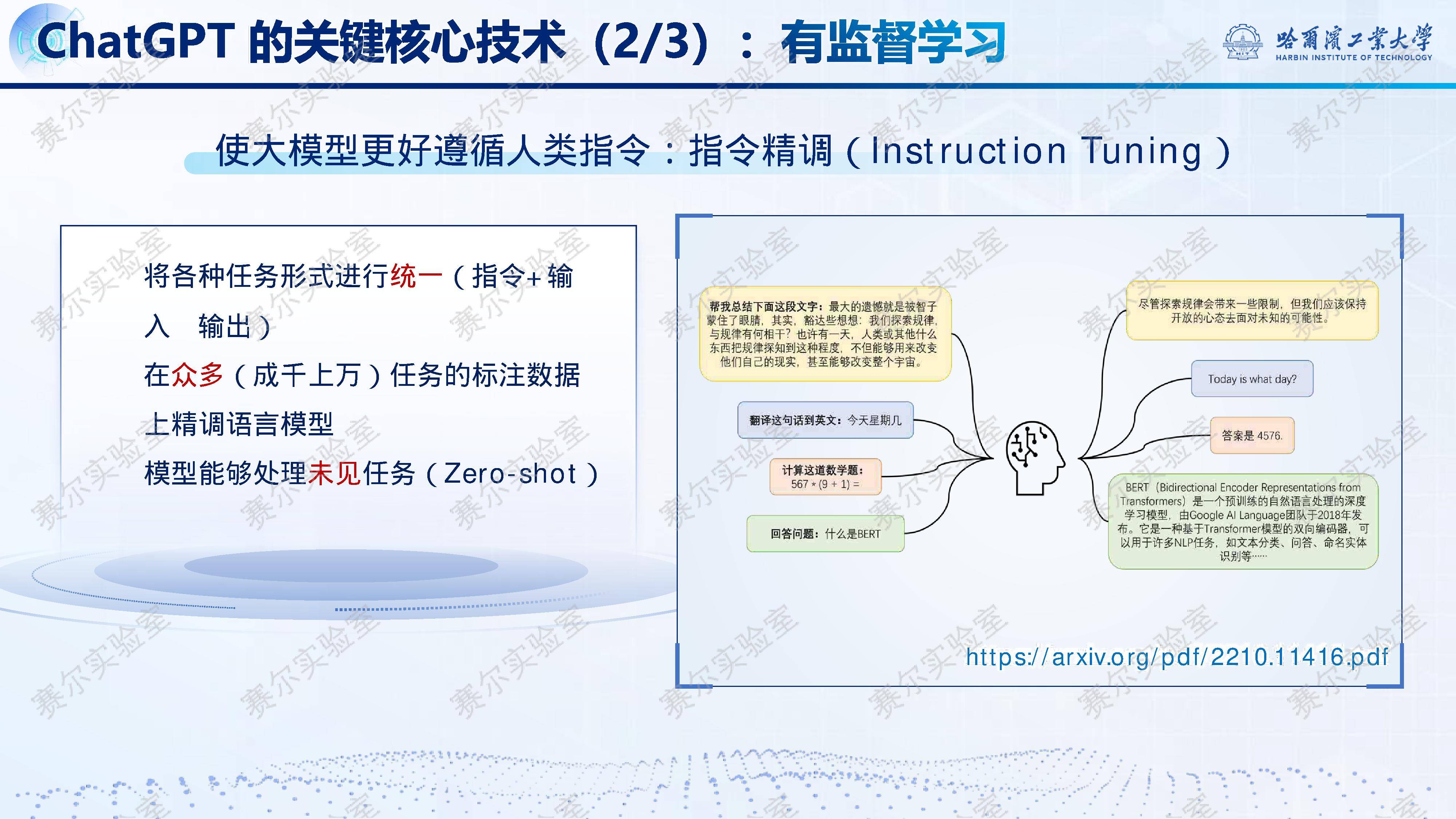
在此基础上,『DeepSeek』-R1进一步融合冷启动SFT与多阶段RLHF,显著提升输出规范性、可读性与泛化能力,最终将AIME得分推至79.8%。同时,其架构层面的极致优化——包括『DeepSeek』MoE混合专家、多头隐含注意力(MLA)、多词元预测(MTP)及FP8/DualPipe等基础设施革新——使671B参数模型以远低于Llama系列的成本高效训练与推理。尤为难得的是,该模型坚持完全开源,被Nature News誉为“震撼科学界的中国开源大模型”。
以下为报告节选内容