唉,说到数据采集,我真是头疼过好一阵子。
你们有没有那种,为了找点资料,在浏览器里开了几十个标签页,复制粘贴到手抽筋的经历?
我反正有。
而且最后还发现,数据对不上,格式乱七八糟。白干了。
说白了,就那几样。
最原始的,手动采集。眼睛看,手复制。准是准,但你试试一天搞几百条?手腕先废了。
还有用Excel导入?那得别人给你规整好的数据才行。现实哪有那么美好。
我以前也觉得,自己动手,丰衣足食。
但漏数据、格式错、速度慢……这些问题,不是靠细心就能解决的。尤其是需要长期、大量采集的时候。人不是机器,会累,会走神。
我后来发现,很多声称“手工整理”的数据报告,背后可能根本不是那么回事。
很多人一上来就想学Python写爬虫。
听起来很酷对不对?自动抓取,效率翻倍。但 IP 被封、网站结构一变代码就废、还有法律风险……这些坑,新手根本想不到。
更别说维护了。今天这个站改版,明天那个站加验证码。你是在做数据采集,还是在当爬虫的专职保姆?
而且,很多平台明确禁止爬虫。你辛辛苦苦搞了半天,一封律师函过来,全完。
所以问题来了,有没有一种办法,既能自动抓,又省心?
这就是我后来才搞明白的。现在的工具,早就不是简单的“爬虫”概念了。
jrhz.info比如我后来用的一个叫优采云的东西(唉,不是广告,纯属个人掉坑后的血泪经验)。它把整个流程都打包了。
你不用管什么IP池、反爬策略、解析规则。你只需要告诉它:“我要这个主题的文章”,或者“盯着这几个网站的新内容”。
它自己会去搜,去抓,还能把乱七八糟的格式处理好。
最让我意外的是,它连发bu都包了。抓来的文章,可以直接发到你的网站或自媒体账号上。电脑关机了,它还在云『服务器』上跑。
这感觉就像……你请了一个不知疲倦的助理,7x24小时给你干活。
当然,如果目标平台提供官方API,那肯定是首选。
稳定,合规,数据规范。但问题是,不是每个网站都开放API啊!特别是那些内容平台,巴不得你把流量留在它那里,怎么会轻易把数据给你?
就算有,通常也有调用频率限制,想大量获取?得加钱,或者慢慢等。
RSS是个老古董了,但现在用的人真不多了。
很多网站早就关了RSS输出。就算有,内容也经常是摘要,不全。对于深度的内容采集,RSS有点力不从心。
我为什么提它呢?因为它解决的不是“抓”这一个点。
它是个流水线。从设定目标(关键词或具体网站),到内容过滤(去重、去垃圾、敏感词过滤),再到加工(改写、配图、加链接),最后到发bu(定时、多渠道)。全自动。
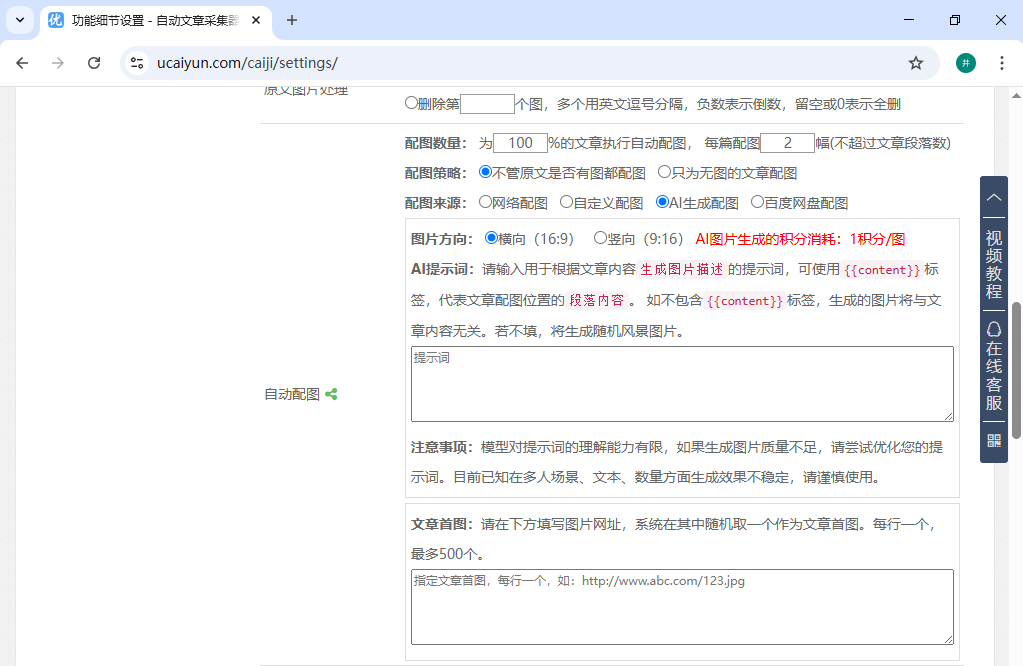
比如,你可以设置只采集最近3天的文章,过滤掉不通顺的垃圾内容,自动给文章配图,甚至把关键词在文章里加粗……这些琐碎的优化,它都能自动完成。
我一开始也不信,设置好之后就没管了。结果第二天登网站后台,发现已经多了十几篇质量还不错的文章。发bu时间还是分散开的,像人工发的一样。
那种感觉,怎么说呢,就像你种下一颗种子,第二天发现它已经开花结果了。你甚至没浇水。
这才是关键对吧?抓一堆垃圾回来有什么用。
传统方式很难保证。但现在的AI工具,能在采集时就做初筛。通顺度、相关性、长度、重复度……都能设门槛。
优采云里就有好多层过滤设置。你可以让它只抓相关度90%以上的,屏蔽带敏感词的,过滤掉太短或太长的。甚至能防止抓到内容相似的文章。
这基本上把后期的清洗工作,前置了一大半。
哈,这是个好问题,也是个灰色地带。
直接复制粘贴肯定不行。所以需要“加工”。深度改写,甚至AI原创。优采云里面就有深度原创功能,它不是简单的替换同义词,而是基于你的要求重新组织生成一篇文章。
当然,原创度这东西,见仁见智。但它至少提供了一种可能,让你在合规的框架内,高效地生产内容。
我觉得吧,看需求。
如果你就偶尔抓点数据,手动或者写个简单脚本也行。
但如果你是网站站长、自媒体运营,需要持续的内容供给,那真的需要一个系统性的解决方案。它得稳定,得省心,得能把采集、处理、发bu连成一条线。
我后来想通了,我的核心是运营好内容,而不是成为爬虫专家。工具应该让我更专注在核心上,而不是消耗在无尽的调试和维护里。
用优采云之后,我最大的改变是,我不再焦虑“明天发什么”了。我可以把时间花在选题策划、用户互动上。内容的“原料”供给,交给了这个不知疲倦的AI流水线。
这大概就是现代内容生产的“工业化”吧。虽然听起来有点冷冰冰,但效率,是真香。




