(来源:今日霍州)
今日霍州 3 月 1 日消息,据 THE DECODER 报道,新一代『大语言模型』(从 GPT-5 及后续版本开始)在任务需要跨多轮对话完成时,表现依然不佳。研究员菲利普 · 拉班(Philippe Laban)及其团队在代码、数据库、操作指令、数据转文本、数学计算、文本摘要这六大任务上对现有模型进行了测试。当信息被拆分到多条消息中(分片式),而非集中在单次提示词里(拼接式)时,模型性能会显著下降。
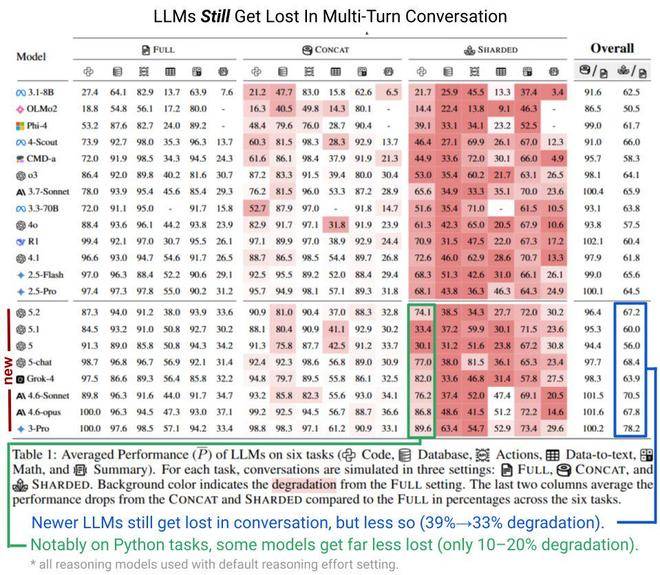
今日霍州注意到,更新的模型表现略好一些,性能降幅从 39% 缩小到 33%,但问题远未解决。Python 任务的提升最为明显,部分模型仅损失 10%–20% 的性能。拉班认为,实际场景中的性能损失可能更严重,因为测试只使用了简单的用户模拟;如果用户在对话中途改变想法,性能下降幅度可能会更大。
原始研究发现,调低温度值(temperature)这类技术微调无法解决这一问题。研究人员建议:一旦出现异常,重新开启一段新对话,最好先让模型把所有请求总结一遍,再用这份总结作为新对话的起点。




