")

长期以来,随机对照试验(RCT)被视为临床证据的“金标准”,但实际实施过程中RCT往往不可行,太昂贵或不符合伦理。
因此,观察性研究成为重要的替代手段。然而,优势同样伴随着风险,观察性研究很容易引入偏倚。正因如此,STROBE声明才强调:观察性研究必须接受严格评估。
今天分享一篇发表在《Intensive Care Medicine》(医学一区top,IF=21.2)文章,探究团队旨在加强读者对观察性研究的评估,总结了此类研究中的关键方法和统计考量。
研究团队首先提炼出9个核心问题,这9个问题看似零散,实则可以归类为三个主线:
- 因果关系的有效性(问题1、2、5、6):我们看到的关联是真实的吗?
- 数据的完整性(问题3、7):数据是否可靠?缺失和多重比较是否扭曲了结论?
- 模型的可靠性(问题4、8、9):模型本身靠谱吗?结论能推广吗?

对于些问题,研究团队是如何解答的呢?下面我们一条一条拆解。
问题1:调整混杂变量,必须尊重“时间顺序”
混杂变量是与暴露和结局都相关的变量,若不正确调整会扭曲真实关联。文章强调,调整混杂变量时必须尊重时间顺序。
- 只有发生在暴露之前、或者和暴露同时发生且不受其影响的变量,才有资格进模型。暴露发生后才出现的变量,哪怕看着像混杂,也不能调,否则偏倚更大。
举个例子,一项研究探讨“既往健康”对脓毒症短期死亡率的影响。年龄是基线混杂变量,应在模型中调整。
如果考虑阴离子间隙水平也可能是短期死亡率的混杂因素,则应在入院时测量,而不是在随访期间测量,以避免暴露后变量引入偏倚。
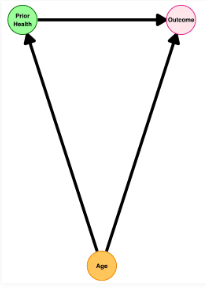
问题2:构建DAG,避开“碰撞偏倚”的陷阱
有向无环图(DAG)是基于先验知识绘制的因果图,用于识别哪些变量需要调整、哪些不能调整——尤其是碰撞变量。文章强调,DAG不能证明因果关系,但能帮助研究者识别潜在的碰撞偏倚。
例如,在前面提到的脓毒症研究中,患者按CDC标准(血培养阳性+至少4天抗生素)入选。
- 有合并症的患者因治疗更积极,更早达到标准;
- 而健康患者较晚才达到。
结果,在入选人群中“既往健康”反而与更差的结局相关。
这里的CDC标准就是一个碰撞变量——它同时受暴露(健康状态)和结局的决定因素(疾病严重程度)影响,对它的条件限制产生了虚假关联。
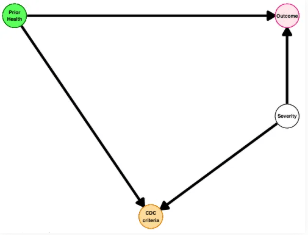
【特别补充】中介变量:别把它当混杂调了!
中介变量位于暴露和结局的因果路径上。也就是,暴露先影响中介,中介再影响结局。
举个例子,还是前面那项脓毒症研究。
先前的健康状态会影响入院时的肾小球滤过率(GFR),而GFR的好坏又会影响短期死亡率。
在这里,GFR就是一个中介变量——它解释了“为什么健康的人结局更好(或更差)”。

文章特别提醒,中介变量和混杂变量,在模型里处理方式完全不同。
- 混杂变量:必须调整,否则关联是偏的。
- 中介变量:不能当作普通协变量直接调整!一旦调整,就等于切断了暴露→中介→结局这条路径,反而会低估真实的总效应。
想研究中介作用,需要用专门的中介分析方法,而不是把它扔进多因素回归里了事。
问题3:缺失数据怎么处理?先看机制和比例
观察性研究几乎必然存在缺失数据,关键是如何处理。文章提醒读者盯住三件事:
- 缺失机制是完全随机缺失(MCAR)、随机缺失(MAR)还是非随机缺失(MNAR)?
- 是否展示了缺失模式图?
- 是否比较了完整数据与不完整数据患者的基线特征?
若为MCAR或MAR且缺失比例不高,可采用多重插补,但当缺失超过60%时应谨慎。
问题4:谨慎选择模型,警惕“过拟合”
过拟合指模型过度贴合训练数据,失去对新数据的推广能力。文章指出,过拟合的影响因建模目的而异。
- 预测模型若过拟合,会高估预测效能;
- 调整模型若过拟合,则可能导致效应估计不稳定。
可采用惩罚回归(如Lasso)、交叉验证等技术控制模型复杂度。文章特别提醒,“每个协变量10个事件”的经验法则并非铁律,模拟研究表明,许多方法可适应更少的每个协变量事件数。
问题5:倾向性评分,必须看“共同支持”和“协变量平衡”
倾向性评分(PS)是观察性研究中最常用的调整方法之一。研究团队指出,读者应重点关注两个关键信息:
- 第一,共同支持区域:即治疗组和未治疗组PS分布的重叠程度。加权之后两组曲线能叠在一起,才说明可比性有了基础。
- 第二,协变量平衡:加权后各协变量的标准化均值差(SMD)应降至0.1以下,表明组间协变量已达到平衡,可比性增强。

另外,PS加权和PS匹配回答的是不同问题:
- 加权:干预在全人群的效果(ATE)
- 匹配:干预在实际治疗者中的效果(ATT)
选择哪种,取决于临床问题。
问题6:稳健性+敏感性,双重检验更可靠
即使经过PS调整,观察性研究仍无法完全排除未测量混杂的影响。这时候得看两个分析:
- 稳健性分析:结果会不会被一两个极端值带跑?
- 敏感性分析:改一下假设,结果还稳吗?
常用工具是E值——算出来数值越大,说明结论越扛打。如果不同的统计方法得出一致的结果,则可信度再加分。
问题7:多重比较,校正与否是个问题
观察性研究经常一次测一堆假设,假阳性风险(I类错误)自然高。但也有学者提醒,过度校正可能漏掉真发现(II 类错误),尤其在探索性分析中。
合理做法是,主要结局和关键次要结局,事先定好,不用校;其他结果,就当探索性看看,不宜过度解读。
不过,在组学等大数据研究中,多重比较调整已是常态。
问题8:模型假设,必须在方法部分说清楚
任何统计模型都有其假设——线性回归要求残差正态分布、独立观测;逻辑回归假设对数优势与自变量呈线性关系。
文章强调,作者应在方法部分明确说明这些假设,并描述如何检验。
而最理想的做法是,公开统计代码和数据,让读者能自行验证模型假设。
问题9:结果能否推广?关注“目标人群”
可推广性(即外部有效性)指研究样本的结论能否有效扩展到目标人群。
研究者应当评估:研究样本是否具有代表性?入选标准是否过于严苛?选择偏倚是否可能影响结论?
事实上,研究者应仔细考虑选择偏倚。这种偏倚可能来自于用于选择感兴趣人群的方法,例如,不适当的抽样方法可能导致对结果的误导性解读。
总结
生物统计方法越来越强,观察性研究也能拿出硬核证据。但方法越复杂,解读门槛越高。
这9个问题,其实就是三件事:
- 关联是不是真的?
- 数据是不是稳的?
- 模型是不是对的?
下次看观察性研究,把这9个问题过一遍。能答上来的,值得细读;答不上来的,随手翻翻就行。
方法对了,数据才能说话;方法错了,再大的样本也是噪音。





