12月25日凌晨,『英伟达』和Groq宣布达成“非排他性授权协议”,以200亿美元💵现金价格购买一家“非GPU”架构企业的技术授权。这是『英伟达』有史以来规模最大的一笔投资,该公司将现金和短期持有资本606亿美元💵的三分之一都给了这家公司,超出该公司此前估值的3倍。

这一激进动作与近期谷歌TPU等“非GPU架构”的风头正劲密切相关。『英伟达』收购的这家『芯片』公司Groq的创始人兼CEO是谷歌“TPU『芯片』”的缔造者乔纳森·罗斯(Jonathan Ross),收购后乔纳森及Groq的核心技术成员也将集体加盟『英伟达』。Groq主攻的是独创的LPU——软件定义硬件的可重构数据流架构,消除了内存带宽的瓶颈。这种设计让LPU在处理『大语言模型』时,能实现每秒数百个Token的“瞬时”吐字,这是TPU和传统GPU无法企及的物理极限。业界认为,对于推理环节而言,Groq的可重构数据流可能是最好的技术路径选择。

『英伟达』CEO黄仁勋年初曾表示,他认为AI推理需求将增长百倍。而『英伟达』在岁末这个时点“强势收编”推理优化的低延迟『芯片』制造商Groq,或许已经承认了GPU并非AI推理工作的理想选择,更对外印证了非GPU架构在 AI 算力时代的重要性正日益凸显。
事实上,AI 大模型热潮引发了算力需求暴涨。从文本生成、AI 图像创作到 AI 视频合成,从大规模模型训练到高复杂度推理任务,大模型展现出令人惊叹的能力,这也让AI算力『芯片』在其中发挥关键作用。随着AI应用场景丰富、任务日趋复杂,AI 『芯片』赛道形成了两大泾渭分明的技术流派:一派是以 GPU 为代表的共享式集中计算派;另一派则是以ASIC(谷歌 TPU)、可重构数据流『芯片』(Groq LPU)为代表的非GPU派。
谈到GPU派,门派宗师为『芯片』巨头『英伟达』。GPU架构就像精密的工业流水线,计算单元如同训练有素的工人,在冯·诺依曼架构的框架下高效运转。其最大优势在于数十年精心构筑的成熟软硬件生态,标准化程度高,用户几乎可以即插即用。然而,GPU架构『芯片』的性能提升越来越依赖于制程微缩的极限突破以及HBM带宽的艰难提升。
再来看非GPU派,包括ASIC(专用集成电路)和可重构数据流『芯片』,其中Groq LPU为可重构数据流领域的代表,其精髓在于硬件能够根据瞬息万变的计算任务动态重组,构建出高效专用通道,使得AI『芯片』具备灵活性和专用集成电路高效性的优势。早在2015年,可重构计算就被国际『半导体』技术路线图预见为“未来最具前景的『芯片』架构”。
如今『英伟达』获得的Groq,并非基于GPU进行“小修小补”,而是直接融合已经被验证的强大的可重构数据流架构,从底层构建推理系统,旨在实现AI推理速度、规模、可靠性和成本效益。被称为“高阶TPU”的Groq LPU采用软件定义硬件的数据流式并行架构,基于格罗方德的14nm工艺制造,不包含外部HBM存储,在处理过程中,权重、键值缓存 (KVCache) 和激活值等数据都保存在『芯片』内部,依赖于动态调度模式,可以让数百个核心同步激活张量模型,即可实现40倍于传统方案的推理性能,无需依赖先进制程即可突破能效瓶颈。
2025年7月,Moonshot AI发布开源文本大模型Kimi K2,一度在国际权威榜单LMArena上登顶全球最强开源模型。发布后短短72小时,Groq基于高阶TPU架构的AI云算力系统,将Kimi K2的性能提升40倍,能效比超过『英伟达』GPU。得益于Groq Compiler和Groq RealScale『芯片』间互连技术,Groq『芯片』构建了一个共享的资源架构集群,能够在MoE(混合专家)万亿参数模型上高效运行,提供所需的规模和速度,以跟上不断变化的 AI 模型格局。
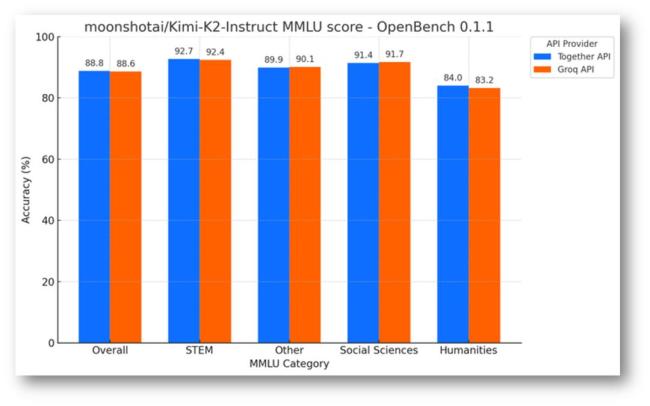
可靠性层面,根据开放式大模型评估框架OpenBench数据显示,Groq与基于『英伟达』GPU 的 API 提供商上Together AI 运行Kimi-K2-Instruct 模型的MMLU实例,结果表明,Groq的准确率更高,在STEM、Social Sciences等方面都比肩GPU AI Infra能力。制造成本层面,用于制造Groq『芯片』的晶圆成本可能低于每片6000美元💵,相比之下,『英伟达』的H100『芯片』采用台积电5nm工艺,其晶圆成本接近每片16000美元💵。最终,Groq『芯片』和单卡成本均低于『英伟达』H100,这对于重算力推理的客户来说性价比更高。
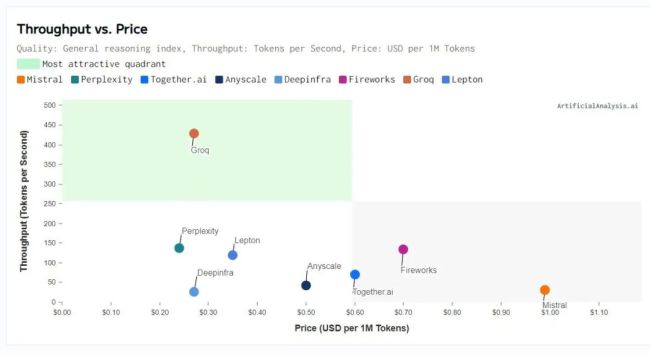
凭借“高阶 TPU”的可重构数据流架构,Groq在推理速度、吞吐效率、成本优化等核心维度形成综合优势,全面对『英伟达』 GPU 构成竞争压力。这或许也是『英伟达』着急收购Groq资产的核心原因。展望下一步,随着这桩200亿美元💵“非典型并购”交易落锤,乔纳森和其他高管将共同助力『英伟达』构建AI工厂。『英伟达』方面表示,Groq的低延迟『芯片』对输入的响应速度极快,将为『英伟达』的产品带来新的能力,帮助其开拓新的市场领域。
当前,『英伟达』这一AI『芯片』市场的“霸主”似乎正迎来些许动摇,市场对『英伟达』的未来投下了新的审视目光。据报道,『英伟达』的大客户Meta正考虑在其『数据中心』大规模采用谷歌自研的AI『芯片』——张量处理单元(TPU),并可能最早于明年开始租用。实际上,随着AI大模型的重心从训练走向推理和Agentic AI,『英伟达』GPU的缺陷日益突出。GPU并非为推理优化,设计初衷是高速并行计算,而不是以最低成本执行重复推理指令。此外,GPU的灵活性意味着其硬件资源在实际推理场景中可能并非最优配置,导致单位能耗的效率不如ASIC。『英伟达』的定价权极高,云厂商往往需要以远高于制造成本的价格购入GPU,形成了强势垄断方案。
因此,在上述诸多背景下,谷歌、Meta、Cerebras Systems等公司都在发力非GPU技术。而『英伟达』最后选择大规模收购Groq公司,以避免“高阶TPU”架构的领导者Groq,将与『英伟达』GPU共同“混战”的局面。早在2025年,谷歌推出第七代TPU Ironwood,不仅是TPU历史上第一款最强推理『芯片』,而且在架构、规模、可靠性、网络与软件系统上等AI基础设施技术层面都进行了重构,在多项关键指标上首次与『英伟达』Blackwell系列实现正面交锋。单『芯片』层面,Ironwood的FP8稠密算力达到4.6 petaFLOPS,略高于Nvidia B200的4.5 petaFLOPS,已跻身全球旗舰加速器第一梯队。更重要的是,一个Ironwood Pod可集成9216颗『芯片』,构成一个超节点,FP8峰值性能超过42.5 exaFLOPS,在特定FP8负载下,该Pod性能相当于最接近竞品系统的118倍。
知名投行花旗认为,『英伟达』短期地位稳固,但同时预测其AI『芯片』市场份额将从90%逐步下滑至2028年的81%。从投资视角来看,『英伟达』以 200 亿美元💵收购 Groq 的交易,不仅创下其自身史上规模最大的并购纪录,更堪称 AI 算力赛道的重磅布局。这笔交易的 “重量级” 显而易见:200 亿美元💵相当于『英伟达』手头近三分之一的资金储备,如此罕见的大手笔,也让市场戏称其是 “用巨额资金买下核心技术 IP”。这背后,恰恰印证了可重构数据流架构的巨大价值 —— “高阶TPU”技术不仅是 Groq 的核心竞争力,更是『英伟达』不惜重金补齐非 GPU 赛道短板、巩固算力领域主导地位的关键所在。
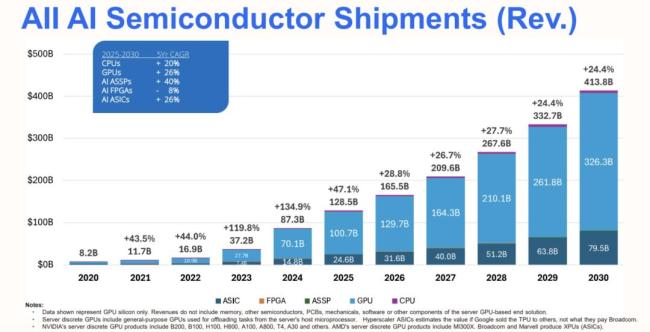
据报道,另一家可重构『芯片』设计公司SambaNova也迎来与Groq一样的收购局面。英特尔正在就收购美国AI『芯片』独角兽SambaNova进行初步谈判,SambaNova公司估值达到50亿美元💵。展望未来,非GPU赛道前景广阔。据国际数据公司(IDC)的最新数据显示,预计2025年,AI算力『芯片』市场规模超过1285亿美元💵,同比增长47.1%,预计2030年AI『芯片』市场规模达4138亿美元💵,其中,非GPU架构『芯片』市场规模占比超过21%,而推理『芯片』占比提升至65%。反观国内市场,IDC数据统计显示,2024年,中国加速『服务器』市场规模达到221亿美元💵,同比增长134%。其中,非GPU加速『服务器』高速增长,占比超过30%。IDC预测,到2029年,中国非GPU『服务器』市场规模占比将接近50%。其中国内ASIC以寒武纪、昆仑芯为代表,可重构数据流则是以清微智能作为这个赛道的标志性企业。




