今天分享的是:生成式人工智能时代的网络搜索特征研究
报告共计:24页
生成式人工智能时代的网络搜索特征研究总结
随着大型语言模型(LLMs)的兴起,网络搜索领域出现了一种新型搜索模式——生成式搜索,其与传统网络搜索在多个核心维度存在显著差异。本文通过对比谷歌传统搜索与谷歌AI概述、Gemini、GPT-4o-Search、GPT-4o搜索工具等四款生成式搜索引擎,在政治、产品评论、科学等多个领域的表现,揭示了生成式搜索的独特特征与发展挑战。
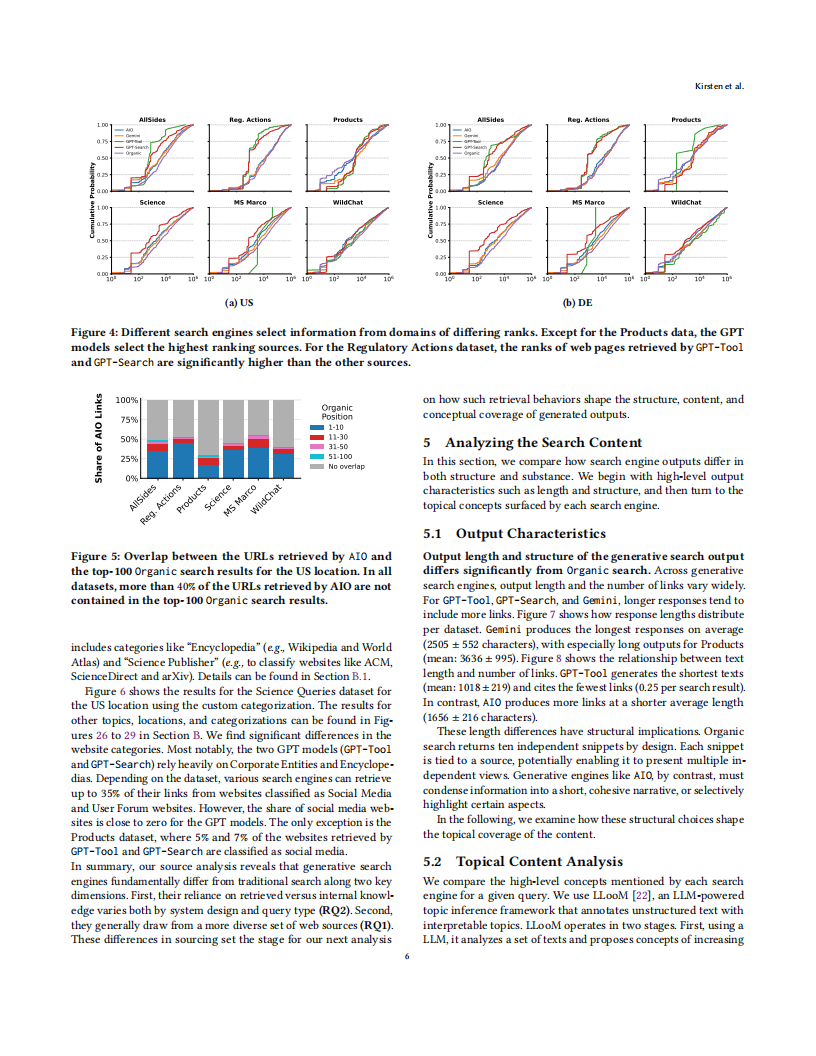
生成式搜索与传统搜索的核心差异体现在三方面。输出格式上,传统搜索返回排名化的独立网页列表,而生成式搜索将信息浓缩为连贯的单一文本响应;信息覆盖范围上,传统搜索通常仅展示前10条结果,用户极少浏览后续内容,生成式搜索则可整合远超10个来源的信息;知识依赖上,传统搜索主要依赖外部网页资源,生成式搜索则结合外部检索信息与模型内部知识。
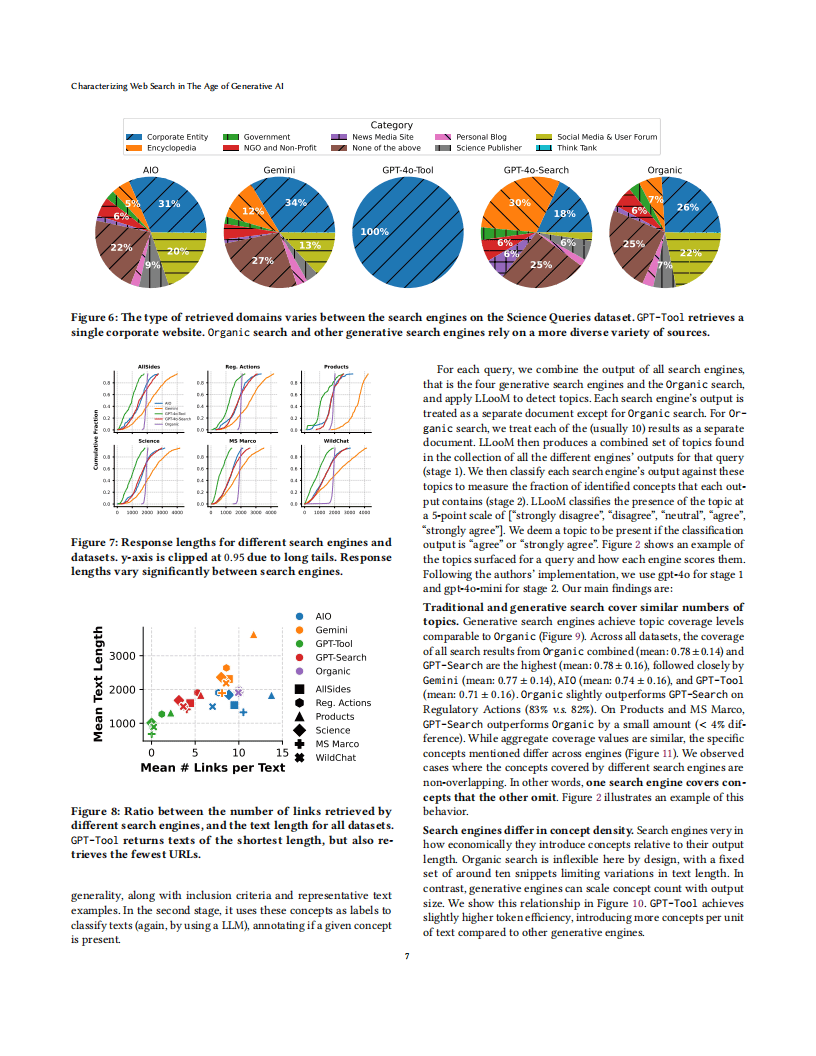
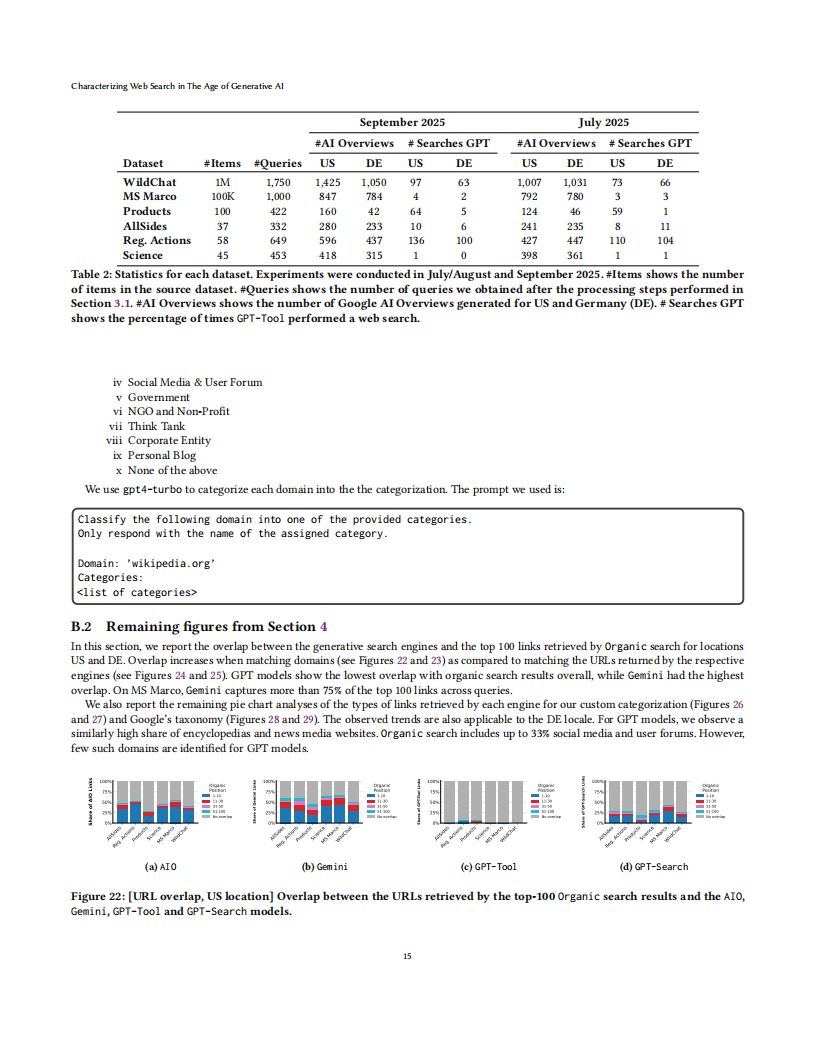
在信息来源方面,生成式搜索引擎的来源选择呈现显著特点。它们覆盖的域名范围更广,平均约53%的域名不在传统搜索前10结果中,85%的域名属于前100万访问量网站,低于传统搜索的89%。不同生成式引擎对外部资源的依赖程度差异较大,GPT-4o搜索工具平均仅参考0.4个网页,而谷歌AI概述平均参考8.6个。此外,生成式搜索的来源类型与传统搜索也存在区别,GPT系列模型更依赖企业实体和百科类网站,而传统搜索包含更多『社交媒体』和用户论坛资源。
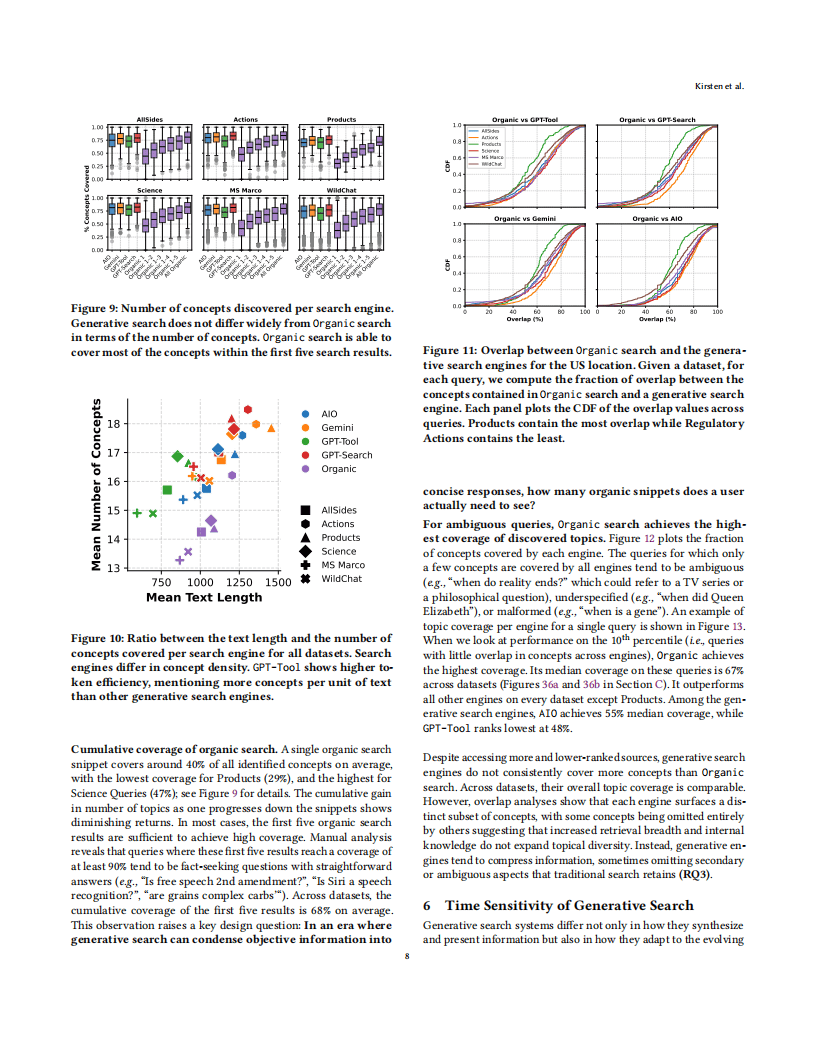
在内容特征上,生成式搜索与传统搜索的主题覆盖率相近,但概念呈现各有侧重。传统搜索在模糊查询中表现更优,其前5条结果平均可覆盖68%的相关概念,而生成式引擎在信息压缩过程中可能遗漏次要或模糊维度。生成式引擎的概念密度存在差异,GPT-4o搜索工具的文本单位概念占比更高,展现出更强的token效率。
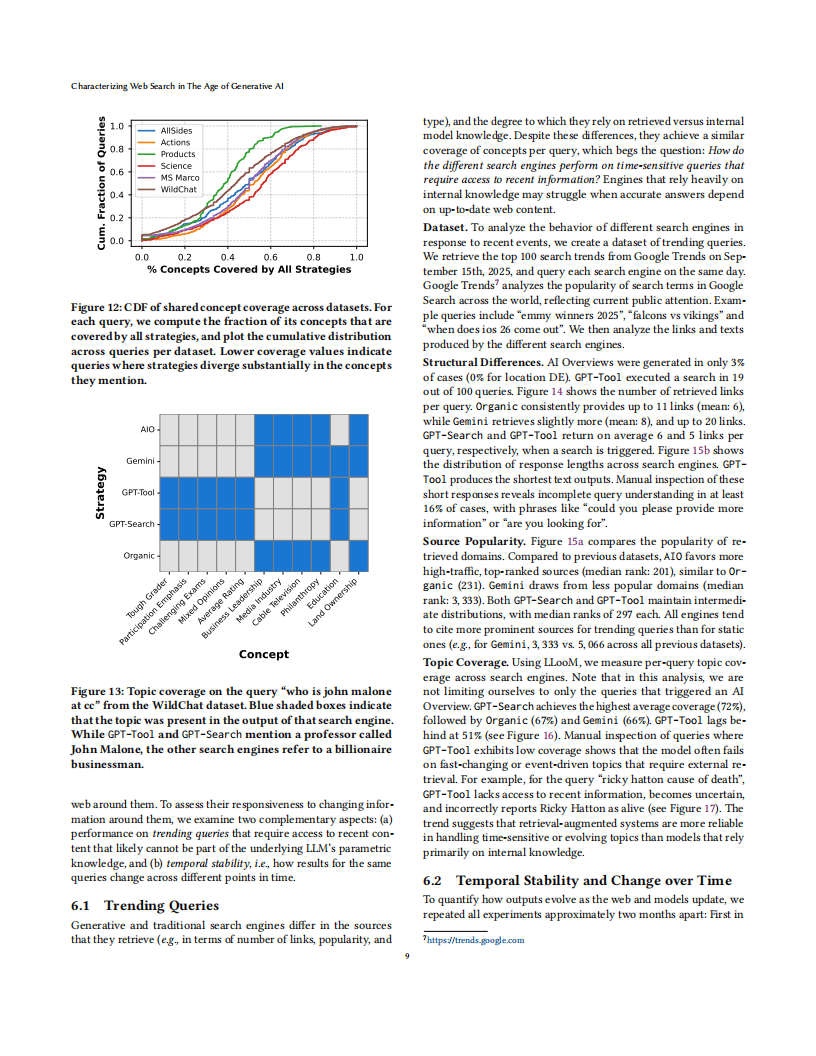
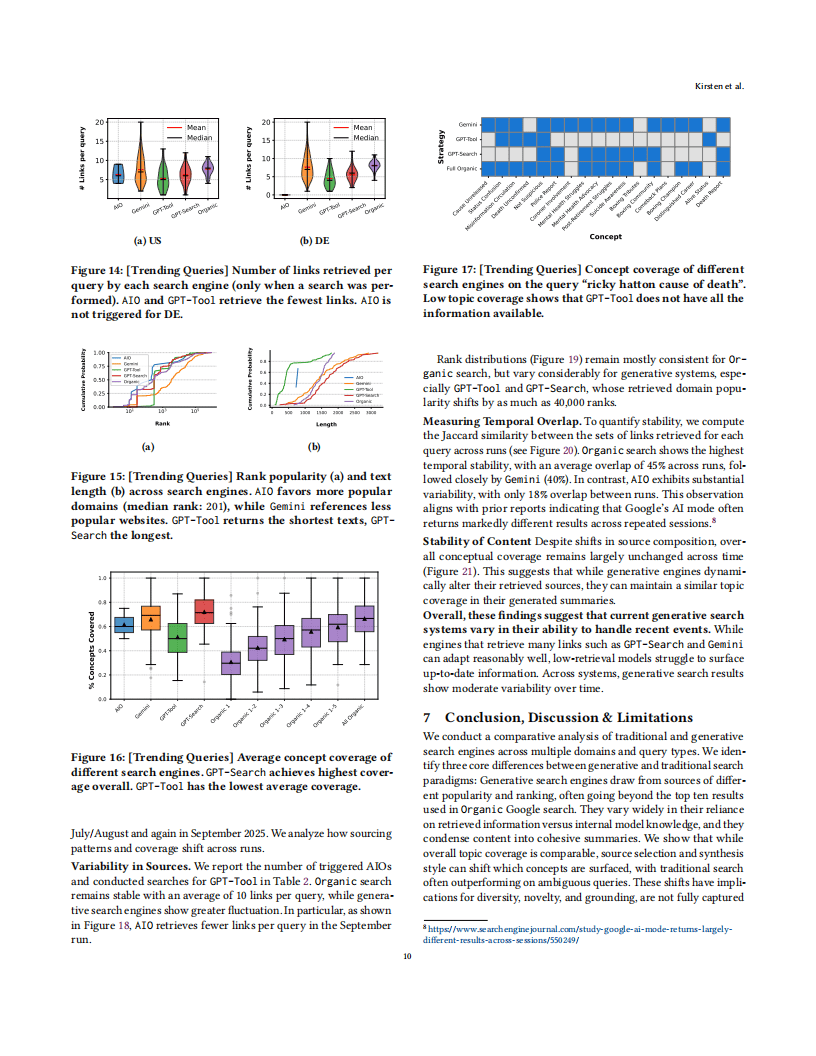
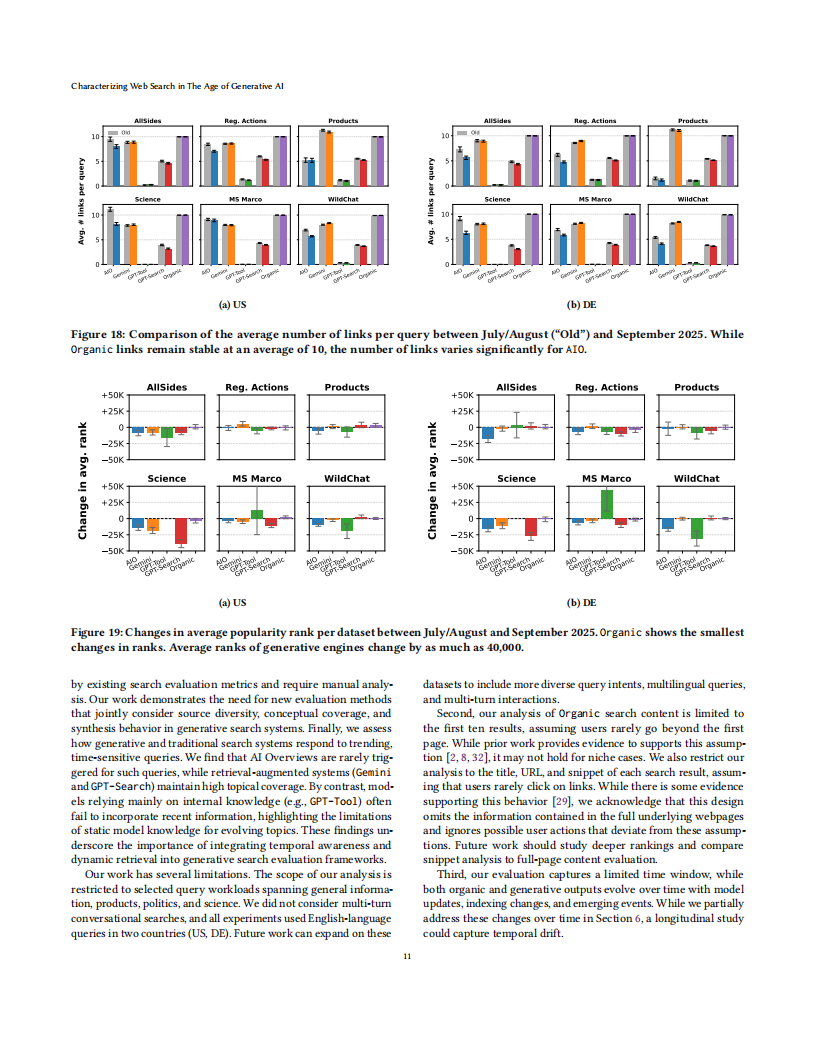
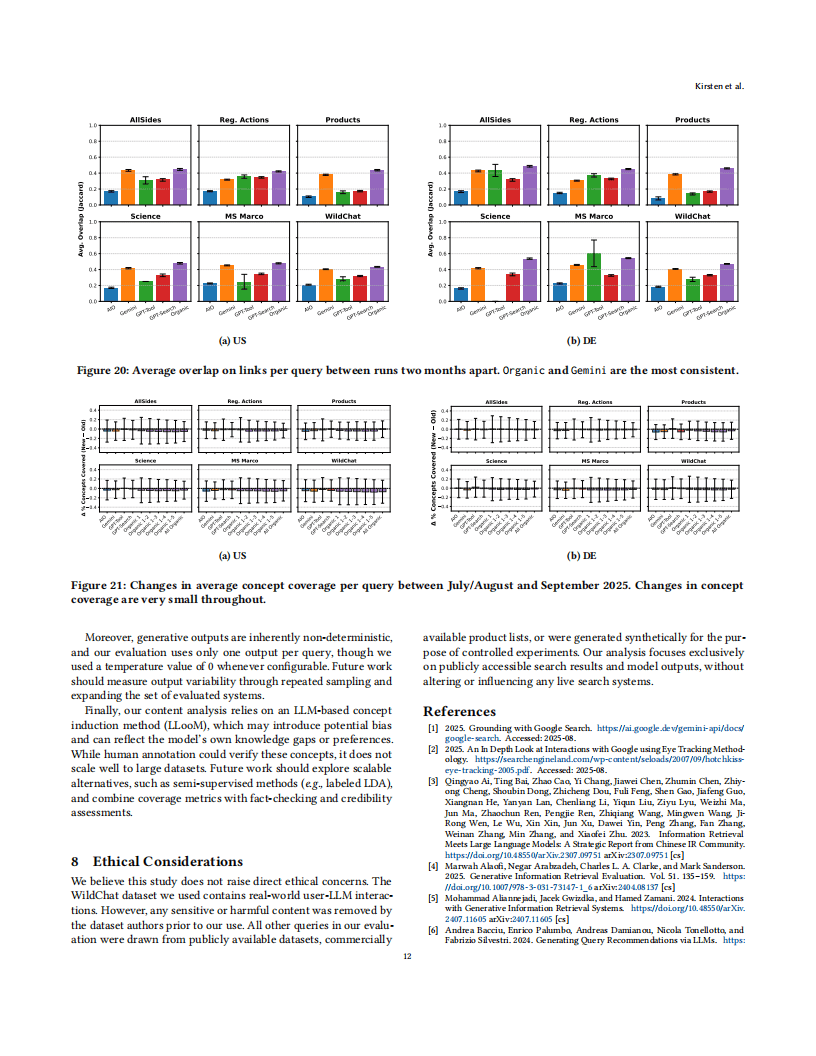
在时效性方面,依赖外部检索的生成式引擎(如Gemini、GPT-4o-Search)在趋势性查询中表现较好,而依赖内部知识的模型则难以整合最新信息。同时,生成式搜索结果的时间稳定性低于传统搜索,谷歌AI概述的结果重叠率仅为18%,而传统搜索达45%。
研究表明,现有搜索评估指标已难以适配生成式搜索,需开发兼顾来源多样性、概念覆盖度和合成质量的新方法。未来研究应扩展查询类型、语言多样性和多轮交互场景,并加强长周期跟踪与全页面内容分析,以更全面地理解生成式搜索的发展潜力与优化方向。
以下为报告节选内容