额……老铁们,我图吧老捡垃圾的了
今天简单看下VIA末代CPU的情况
最近兆芯官网提到了ZX86能让兆芯获得2018年之后的X86新指令集兼容适配问题

加上隔壁还在传谣,所以咱也只能说不信谣不传谣嗷


所以本期是威盛末代CPU——Centaur CHA(CNS)AI CPU资料整理(VIA支持AVX512)回顾
果然咱印象一点都没错,VIA CNS这玩意是有AVX512的
看来没事经常回顾一下已知的参数也是一种好习惯,学而时习之不亦说乎

这说明威盛手上其实是有至少截止到2013年以前所有X86指令集的永久交叉授权的(AVX512发布于2013年)

威盛当年的X86交叉授权有效期原定是到13年截止,后来在反垄断法的帮助下又续了5年

威盛和英特尔可以相互使用对方在2018年4月以前的专利,而且是永久的
这也是龙芯网宣和其他喜欢传播不是信息的自媒体最喜欢混淆的一点
兆芯继承了威盛的X86授权自然是有权使用截止到2018年以前的所有X86指令的
牢英无法通过专利诉讼来卡脖子
然而从结果来看目前的X86指令集支持到AVX512就到头了,后面也没见有什么新指令出来
牢英试图整过X86S烂活,但是很快自己先左右互搏取消X86S计划了
AVX512现在的普及率也不高没有AVX512的CPU大把也没见跑不了现代软件
所以这事说实在的没啥意义
还是看看威盛首创的X86 AI CPU吧
相关资料:化敌为友?英特尔对威盛提供授权延至2018年
【转】了解Centaur CHA(威盛半人马CNS)的物理实现与双槽测试
【转】兆芯CPU架构分析外文资料04《深入研究威盛半人马最后的CPU:CNS》
本不该由我上手的原型CPU - 威盛Centaur AI加速原型CPU#linus谈科技
techpowerup/centaur-cha
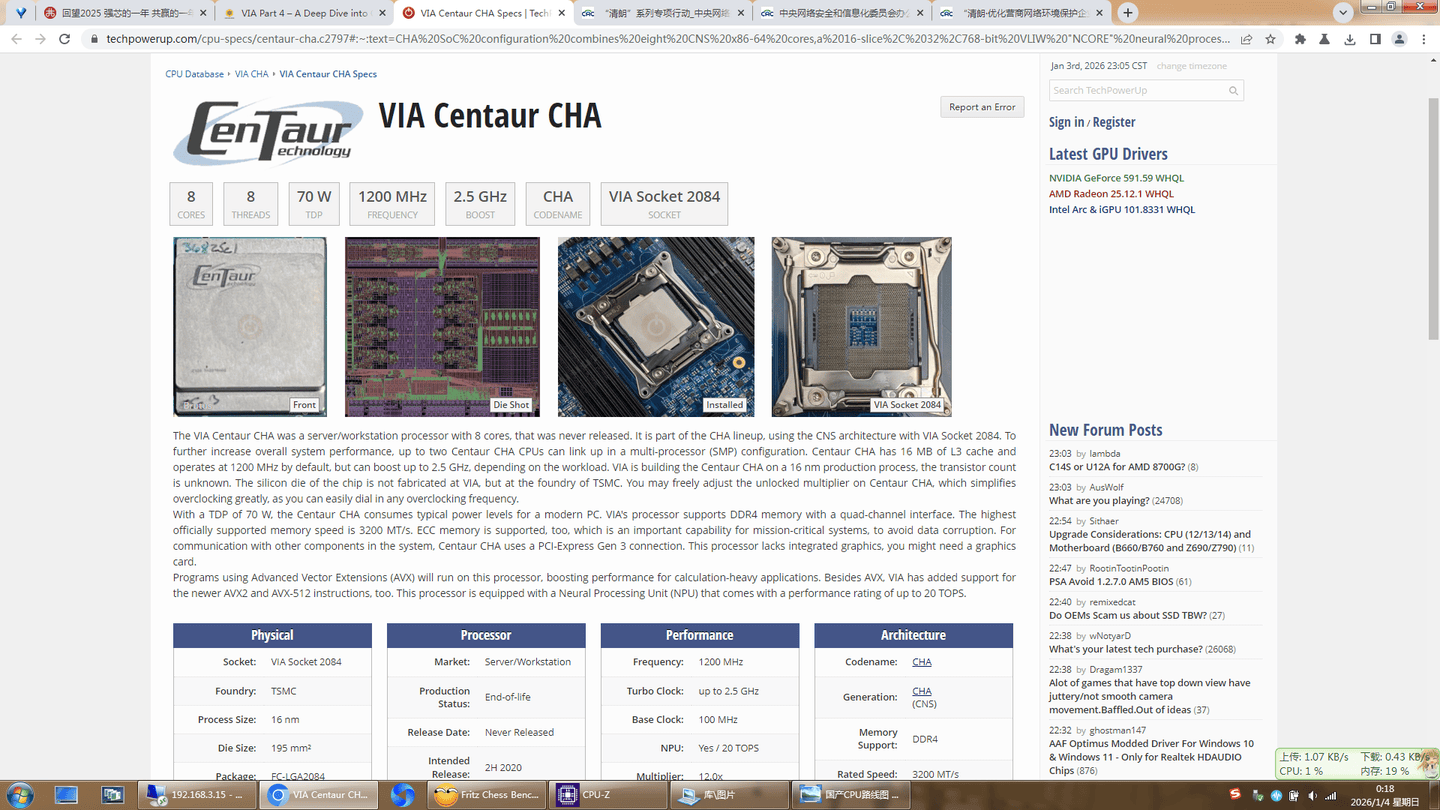

VIA Centaur CHA
8CORES
8THREADS
70 WTDP
1200 MHzFREQUENCY
2.5 GHzBOOST
CHACODENAME
VIA Socket 2084SOCKET

Brutus
Front

Die Shot

Installed

VIA Socket 2084
The VIA Centaur CHA was a server/workstation processor with 8 cores, that was never released. It is part of the CHA lineup, using the CNS architecture with VIA Socket 2084. To further increase overall system performance, up to two Centaur CHA CPUs can link up in a multi-processor (SMP) configuration. Centaur CHA has 16 MB of L3 cache and operates at 1200 MHz by default, but can boost up to 2.5 GHz, depending on the workload. VIA is building the Centaur CHA on a 16 nm production process, the transistor count is unknown. The silicon die of the chip is not fabricated at VIA, but at the foundry of TSMC. You may freely adjust the unlocked multiplier on Centaur CHA, which simplifies overclocking greatly, as you can easily dial in any overclocking frequency.
With a TDP of 70 W, the Centaur CHA consumes typical power levels for a modern PC. VIA's processor supports DDR4 memory with a quad-channel interface. The highest officially supported memory speed is 3200 MT/s. ECC memory is supported, too, which is an important capability for mission-critical systems, to avoid data corruption. For communication with other components in the system, Centaur CHA uses a PCI-Express Gen 3 connection. This processor lacks integrated graphics, you might need a graphics card.
Programs using Advanced Vector Extensions (AVX) will run on this processor, boosting performance for calculation-heavy applications. Besides AVX, VIA has added support for the newer AVX2 and AVX-512 instructions, too. This processor is equipped with a Neural Processing Unit (NPU) that comes with a performance rating of up to 20 TOPS.
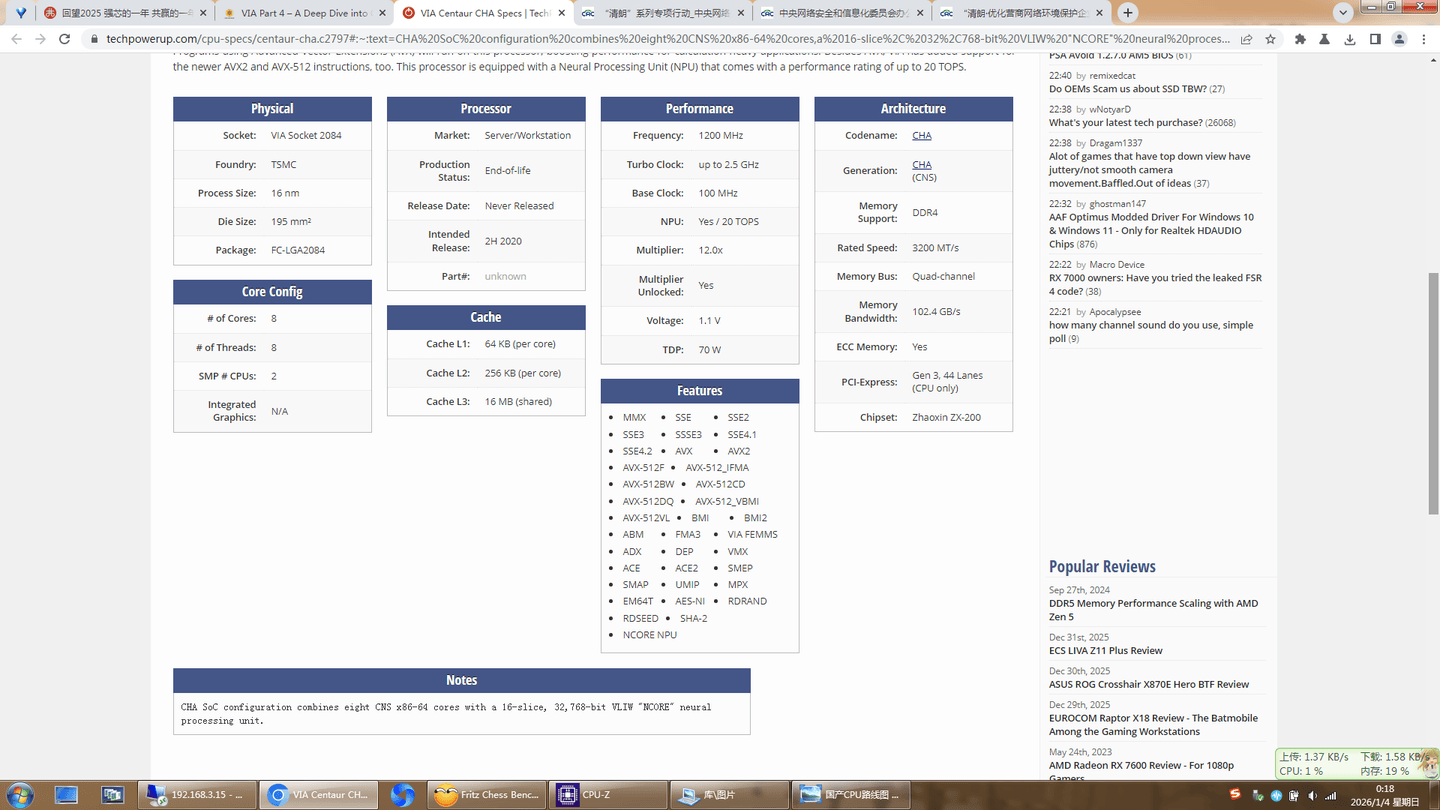
Physical

Processor

Performance

Architecture

Core Config

Cache

Features




































Notes

翻译:
威盛Centaur CHA是一款拥有8个核心的『服务器』/工作站处理器,但从未正式发布。它属于CHA系列产品,采用CNS架构并使用威盛Socket 2084接口。为进一步提升整体系统性能,最多可将两颗Centaur CHA处理器以对称多处理器(SMP)模式进行互联。Centaur CHA配备16MB三级缓存,默认运行频率为1200MHz,可根据负载动态提升至2.5GHz。该处理器采用16纳米工艺制造,具体晶体管数量未公开。『芯片』硅片并非由威盛自主生产,而是委托台积电代工制造。Centaur CHA支持自由调节解锁倍频,极大简化超频操作,用户可轻松设定任意超频频率。
该处理器TDP为70瓦,功耗符合现代PC标准。VIA处理器支持四通道DDR4内存,官方最高支持内存频率为3200 MT/s。同时支持ECC内存,这项关键功能可避免任务关键型系统中的数据损坏。Centaur CHA通过PCI-Express Gen 3接口与系统其他组件通信。该处理器未集成显卡,需另行配备独立显卡。
支持运行采用高级向量扩展指令集(AVX)的程序,显著提升计算密集型应用的性能。除AVX外,威盛还新增了对新一代AVX2及AVX-512指令的支持。该处理器配备神经处理单元(NPU),性能评级高达20 TOPS。
物理参数
插槽:
VIA Socket 2084
代工厂:
台积电
制程工艺:
16纳米
『芯片』面积:
195平方毫米
封装:
FC-LGA2084
处理器
市场定位:
『服务器』/工作站
生产状态:
停产
发布日期:
未发布
原定发布时间:
2025年下半年
部件号:
未知
性能参数
基础频率:
1200 MHz
睿频频率:
最高2.5 GHz
基础频率:
100 MHz
NPU:
支持 / 20 TOPS
倍频系数:
12.0x
倍频解锁:
支持
电压:
1.1 V
TDP:
70 W
架构
代号:
CHA
代系:
CHA
(CNS)
内存支持:
DDR4
标称速度:
3200 MT/s
内存总线:
四通道
内存带宽:
102.4 GB/s
ECC内存:
支持
PCI-Express:
Gen 3,44通道
(仅CPU)
『芯片』组:
兆芯ZX-200
核心配置
核心数:
8
线程数:
8
SMP支持CPU数:
2
集成显卡:
无
缓存
L1缓存:
64KB(每核心)
L2缓存:
256KB(每核心)
L3缓存:
16MB(共享)
特性
MMX
SSE
SSE2
SSE3
SSSE3
SSE4.1
SSE4.2
AVX
AVX2
AVX-512F
AVX-512_IFMA
AVX-512BW
AVX-512CD
AVX-512DQ
AVX-512_VBMI
AVX-512VL
BMI
BMI2
ABM
FMA3
VIA FEMMS
ADX
DEP
VMX
ACE
ACE2
SMEP
SMAP
UMIP
MPX
EM64T
AES-NI
RDRAND
RDSEED
SHA-2
NCORE NPU
注释
CHA SoC 配置将八个 CNS x86-64 核心与 16 片段、32,768 位 VLIW “NCORE” 神经处理单元相结合。








翻译:全球首款集成AI协处理器的高性能x86 SoC技术公告
Centaur Technology是谁?
• 总部位于德克萨斯州奥斯汀市
• 由首席架构师Glenn Henry创立于24年前
• 曾任职IBM与戴尔
• 开发26款x86架构设计,累计销量达数百万台
• 现成为首家推出集成AI协处理器的x86供应商!
官方MLPerf1测试成绩
(MobileNet分类器延迟最快——330微秒)
ISC East展会演示
展位号#751
实测有效!
[1] MLPerf v0.5推理封闭/预览版经审核提交,2019年9月。MLPerf名称及标识为注册商标™️。
行业挑战:高速推理硬件
需依赖外部x86主机处理器
• 超大规模云端及低功耗移动/物联网之外的庞大推理市场
• 部署于本地或私有『数据中心』,处理安防视频、医疗影像等敏感数据的应用场景
(同时降低云端带宽成本)
• “边缘分析『服务器』”可对多数据流(摄像头、物联网传感器等)进行推理
• 当前主要依赖搭载GPU扩展卡的x86 PC/『服务器』硬件
• 功耗与峰值性能次于成本与外形规格的重要性
• 新型『芯片』即将面世以满足快速/精准推理的激增需求
• 基于ARM(及即将推出的RISC-V)的SoC:专为无需x86架构的功耗受限应用设计
• 面向x86平台的高端加速器『芯片』:通过PCIe/M.2接口连接以抗衡GPU
• x86处理器新增深度学习指令集(如VNNI):需大量昂贵CPU核心处理专用深度学习任务
• 外置加速器增加延迟、成本、功耗、板卡空间及故障点等
• 但x86 CPU效率低下:VNNI在MLPerf1测试中ResNet-50模型仅达53fps/核心
推论:现有x86处理器需外部推理加速器提升效率
[1] MLPerf Inf-0.5-23测试。双英特尔®至强®白金9282处理器(共112核)。离线/可用ResNet-50 v1.5模型(5965.62 fps)= 53.26 fps/核心。
解决方案:集成专用AI协处理器与高速x86核心
• Centaur开发新型x86微处理器,具备高每时钟周期指令数(IPC)特性
• 微架构专为『服务器』级应用设计,支持AVX-512等扩展指令集
• 新型x86技术已通过硅片验证,配备8个CPU核心及16MB L3缓存
• SoC架构提供可扩展平台,含44条PCIe通道及4通道PC3200内存
• 含AI协处理器,16nm台积电工艺下占用面积小于195mm²
• 当前参考平台运行频率达2.5GHz
• x86核心与20 TOPS AI协处理器可并行执行
• 通过专用16MB SRAM向AI协处理器提供20TB/s峰值数据传输速率
“Centaur Technology率先发布集成专用协处理器的x86处理器设计,用于加速深度学习。该协处理器提供超越任何CPU的AI性能,同时释放x86核心专注于仍需x86兼容性的通用任务。”
——《微处理器报告》主编 林利·格温纳普
《微处理器报告》将于2019年12月2日发布深度技术解析。
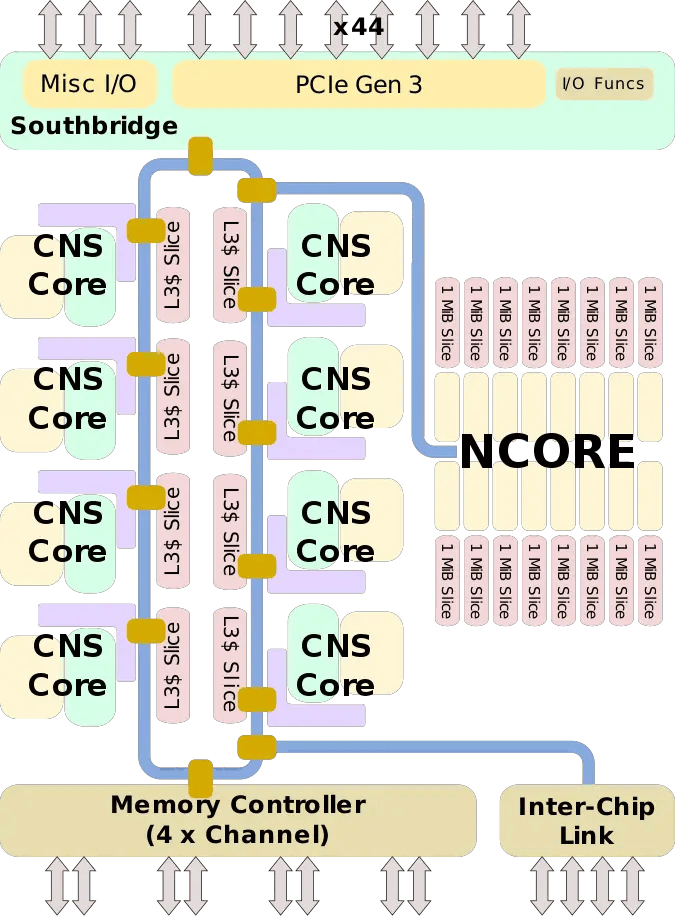
Centaur AI协处理器简介
• 内部代号:“NCORE”
• SoC设计代号“CHA”,x86核心代号“CNS”
• 从零开始设计,追求高效性、可扩展性与灵活性
• 兼具超低延迟特性!
• 采用32,768位超宽SIMD架构,垂直“切片”结构便于灵活调整规模
• SIMD架构显著提升非MAC运算加速效率(如激活函数等)
• 我们在Centaur深谙如何实现高效SIMD运算
• 4096次计算仅需一个时钟周期!故实现极低延迟!
• 远优于大量MAC单元阵列(许多新『芯片』采用)
• 难以快速执行非MAC运算,延迟表现欠佳,扩展性差
• 挑战:内存需求
• 处理视频流中的单帧图像需数百万字节内存
• 需配备海量高速(20 TB/s)内部RAM,并实现DRAM与L3缓存的极速访问
• 每MAC单元专用内存容量远超业界(4 KB/MAC)
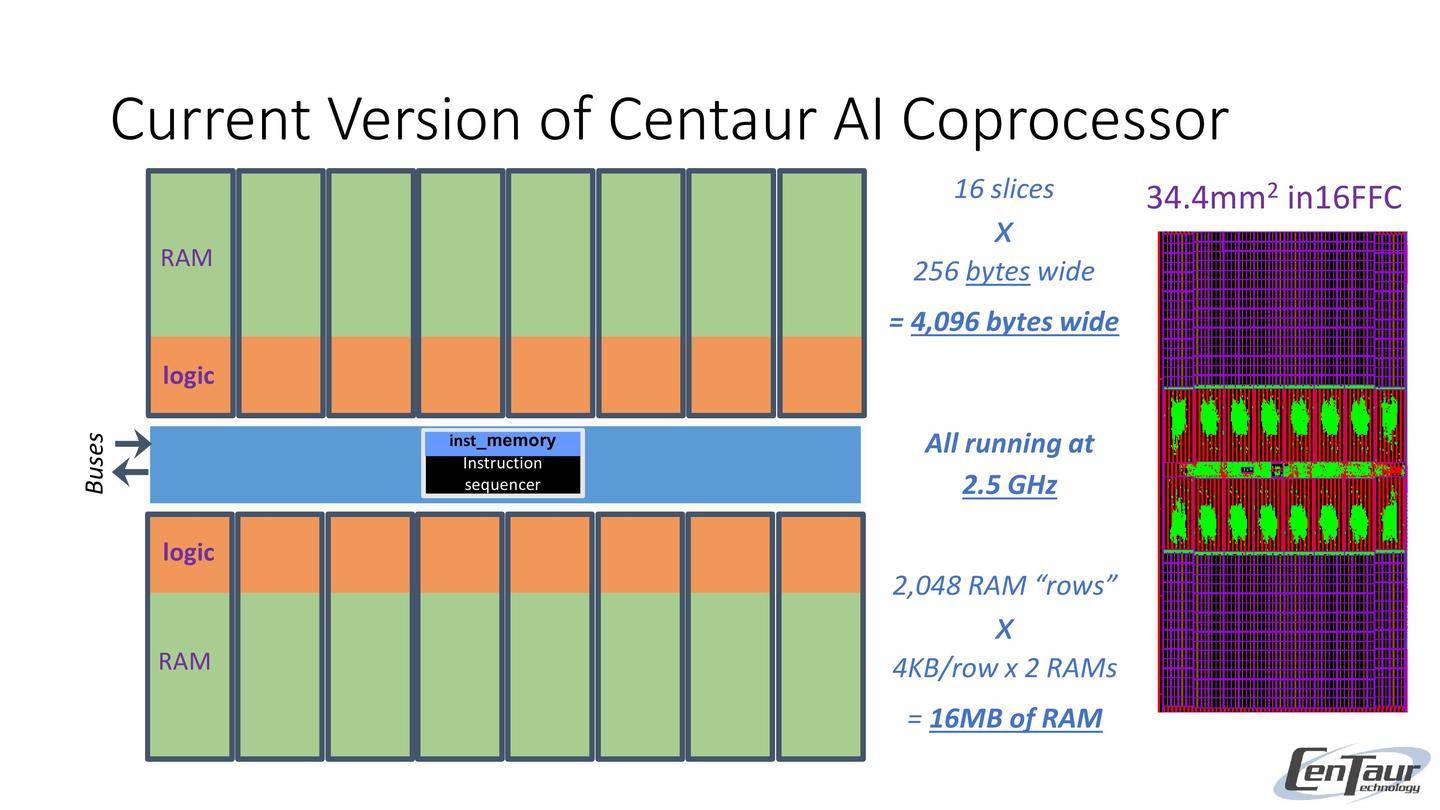
Centaur AI协处理器当前版本
16个切片
×
256字节宽度
= 4,096字节宽度
2,048个RAM行
×
4KB/行 × 2 个 RAM
= 16MB 内存
全部运行于
2.5 GHz
指令内存
指令总线
序列器
RAM
逻辑单元
34.4mm²
in16FFC
RAM
逻辑单元
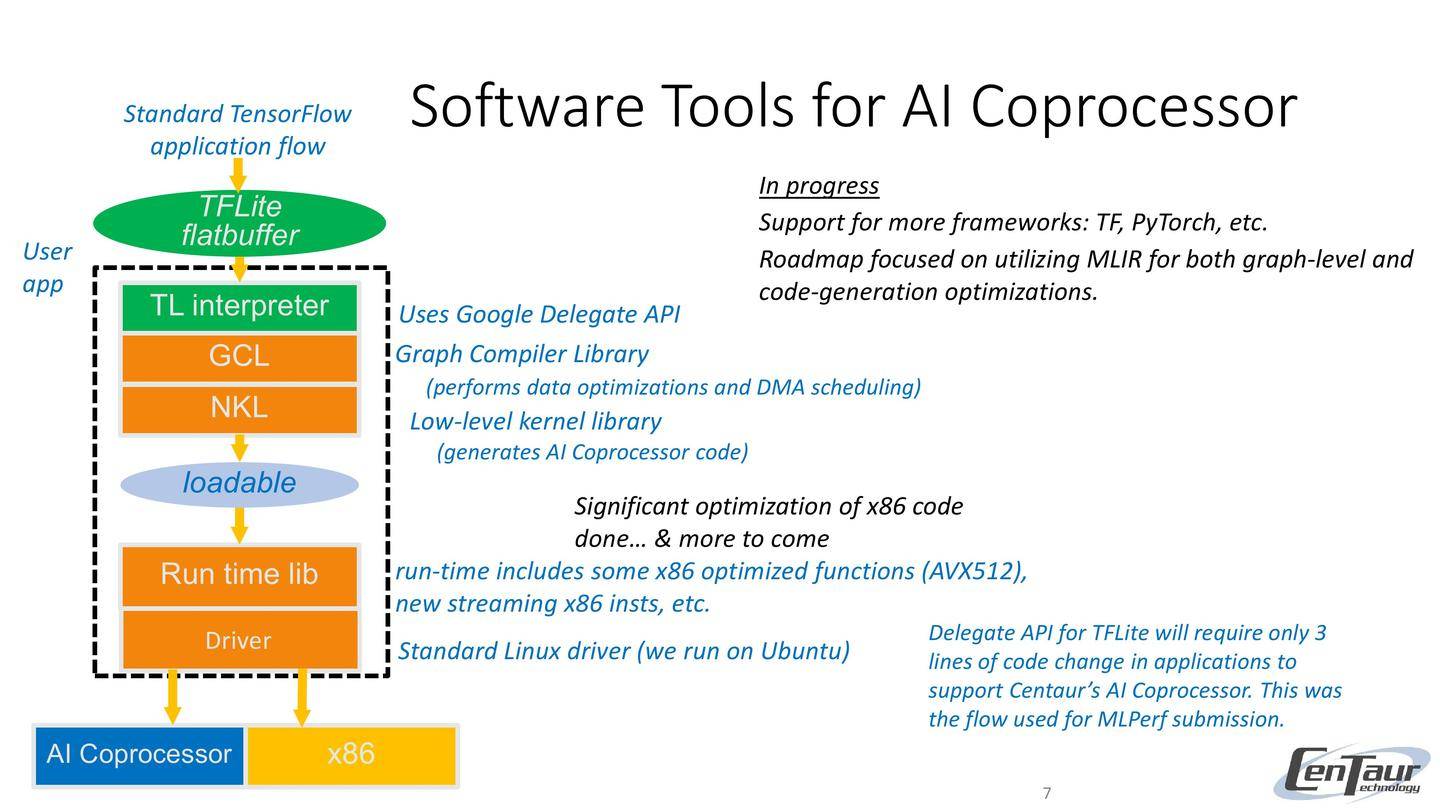
AI 协处理器软件工具
7
TL 解释器
NKL
可加载
驱动程序
运行时库
AI 协处理器 x86
用户
应用
TFLite
FlatBuffer
GCL
使用Google委托API
标准TensorFlow
应用流程
底层内核库
(生成AI协处理器代码)
图编译库
(执行数据优化与DMA调度)
运行时包含部分x86优化函数(AVX512)、
新型流式x86指令等
标准Linux驱动程序(我们在Ubuntu上运行)
进行中
支持更多框架:TF、PyTorch等
路线图侧重于利用MLIR进行图级和代码生成优化。
已完成x86代码的重大优化
...更多优化即将推出
TFLite的Delegate API只需在应用程序中修改3行代码
即可支持Centaur的AI协处理器。此为
MLPerf提交所采用的流程。
MLPerf基准测试
• 逾百家企业和高校参与的卓越基准测试
• Centaur协助推理工作组耗时一年制定基准
• 严谨透明且经审计的方法论——详见v0.5结果及MLPerf白皮书
• Centaur提交了5个应用中的4个(闭门/预览版)
• 软件团队仅有一个月时间调试实际『芯片』,故MLPerf结果未达优化状态
• Centaur将发布非官方结果,其吞吐量表现更优;SSD MobileNet吞吐量将提升3倍
• 如预期所示,大型昂贵系统吞吐量高于单颗195mm² x86『芯片』
• Google的128个TPU v3在ResNet-50测试中实现百万帧/秒!
• Nvidia GPU与初创公司Habana表现优异,但需外部Xeon®主机处理器支持
• 英特尔新款NNP-I硬件等效12个NCORE模块(但MLPerf吞吐量仅提升4.3倍¹)
• 这些扩展卡亦可兼容Centaur系统(支持44条PCIe通道)
• 兼具Centaur AI协处理器的低延迟与扩展卡的高吞吐量优势
“Centaur科技过去一年始终是MLPerf计划的重要贡献者,我们欣喜地看到这家小型企业提交的官方测试结果能与行业领军者直接比肩。其卓越的快速推理延迟表现尤为突出。”
Vijay Janapa Reddi,哈佛大学教授兼MLPerf推理联合主席
[1] MLPerf Inf-0.5-33测试。双英特尔® Nervana™ NNP-I + 4116处理器。离线/预览ResNet-50 v1.5(10567 fps = 5284 fps/『芯片』)。
Centaur在MLPerf测试中的亮点
• MobileNet-V1图像分类
• Centaur实现所有提交方案中最佳MobileNet延迟(330微秒)
• 吞吐量相当于23.2个Intel VNNI核心¹;非官方结果将超过6500 fps
• SSD MobileNet-V1目标检测
• 1.54毫秒延迟距最快提交仅差140微秒
• 因优化时间不足导致吞吐量受限;非官方结果将突破2000 fps(3倍提升)
• ResNet-50 V1.5图像分类
• 每帧延迟约1毫秒,该模型需25.5MB权重及超过4GMACs/图像
• 吞吐量相当于22.9个Intel VNNI核心²;非官方结果将超过1400 fps
• GNMT文本翻译
• 唯一提交结果的『芯片』厂商:证明架构可处理263.3MB权重、RNN及bfloat16
• 未优化结果为12句/秒(4 GMACs/句);非官方结果至少达30
[1] MLPerf Inf-0.5-23测试:MobileNet-V1在112核运行(29203 fps)= 260.7 fps/核。需23.17核方可匹敌Centaur(6042 fps)
[2] MLPerf Inf-0.5-23测试:ResNet-50 v1.5在112核运行(5965.6 fps)= 53.3 fps/核。需22.9核方可达到Centaur性能(1218.5 fps)
总结——全球首款x86集成式AI协处理器!
• 搭载全新高性能x86微处理器设计
• 官方MLPerf测试成绩媲美顶尖AI硬件厂商
• 将AI集成至x86主机带来延迟与成本优势
• 专用AI协处理器效率超越新型x86指令集
• 需23个英特尔世界级x86 VNNI核心方可匹敌Centaur协处理器
• 节省能耗与成本,同时释放x86核心处理通用任务
• 实际运行验证!于ISC East展会演示视频分析应用


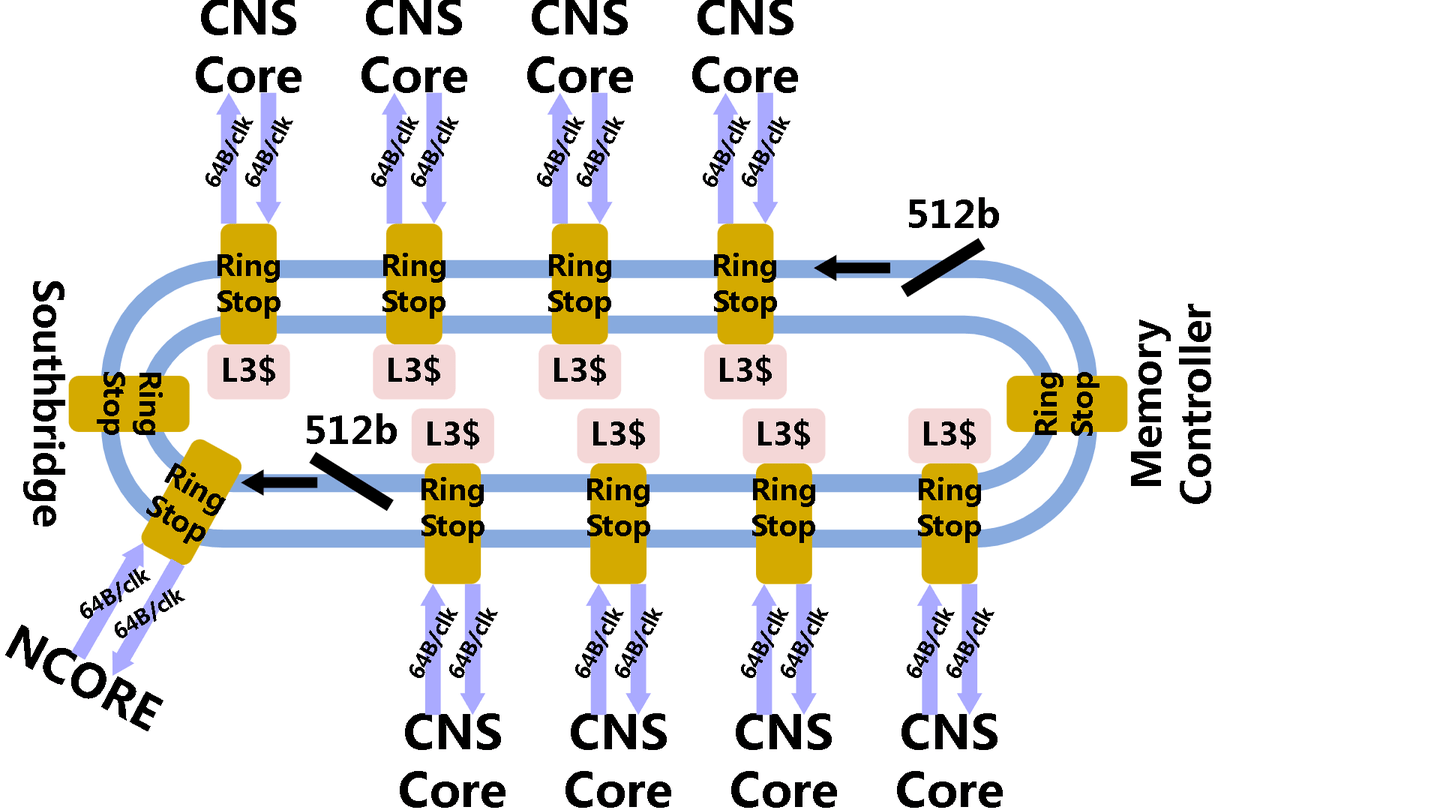
不难发现,这个CNS的板子上有很多兆芯相关的设计


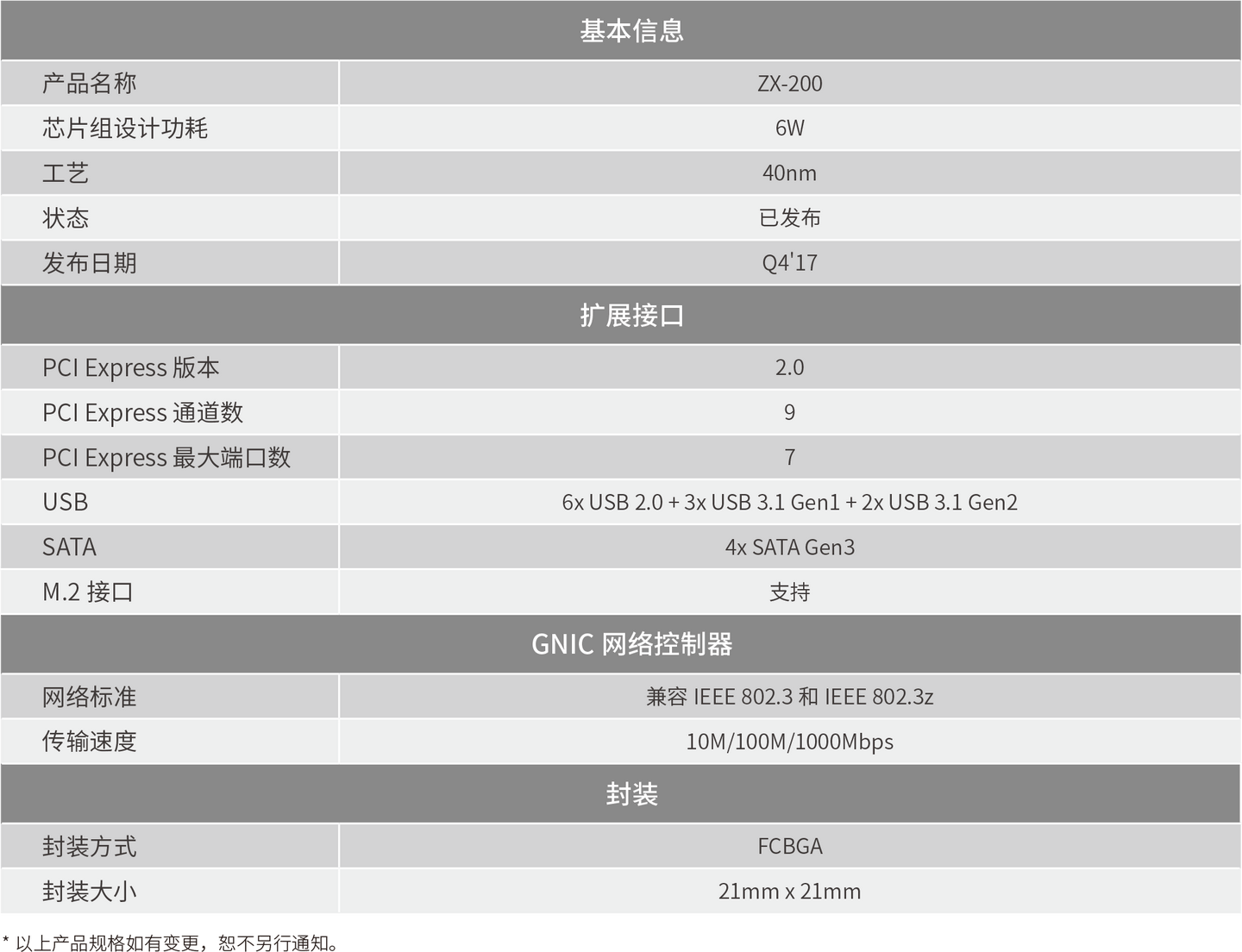
比如ZX200 IO扩展『芯片』

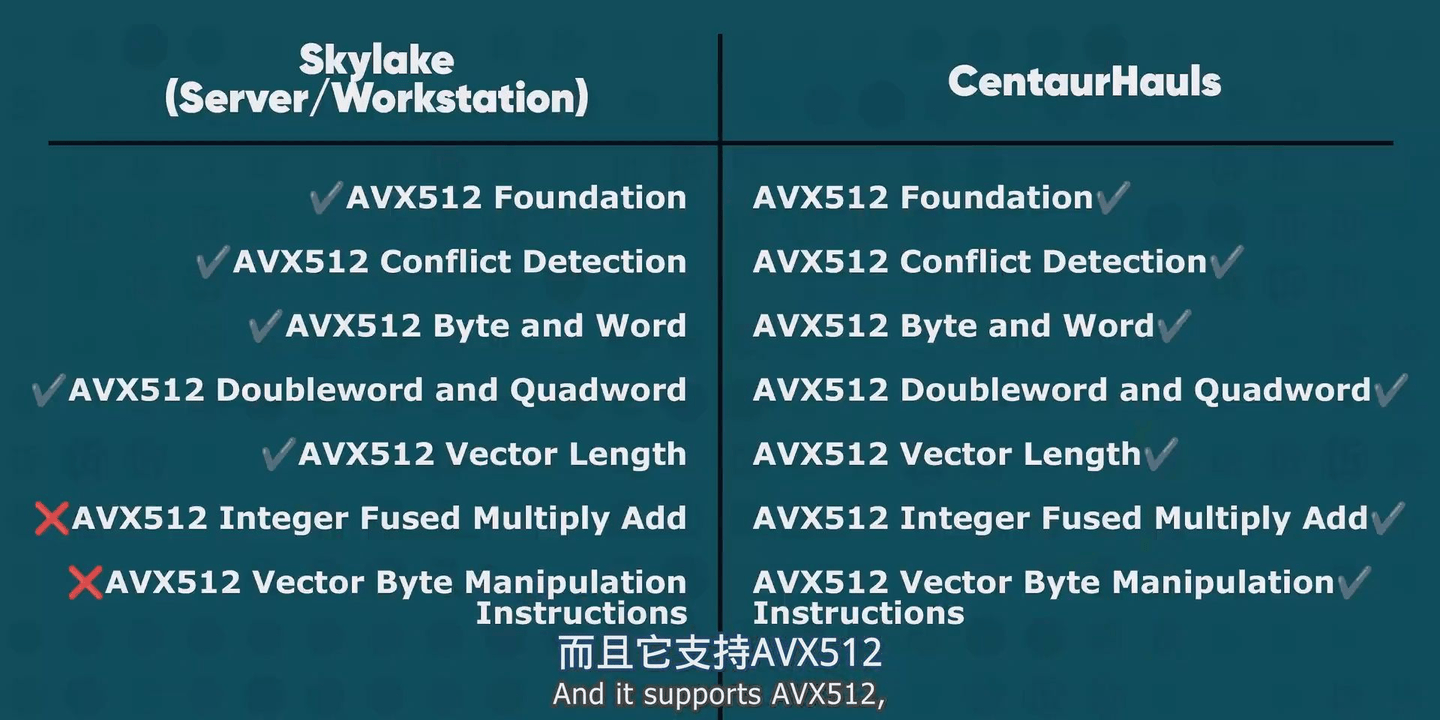
而且这东西它是确信支持AVX512的

它有四通道DDR4支持,而且自带一个NPU(可共享CPU L3)
非常符合传说中的嵌入式AI CPU的需求

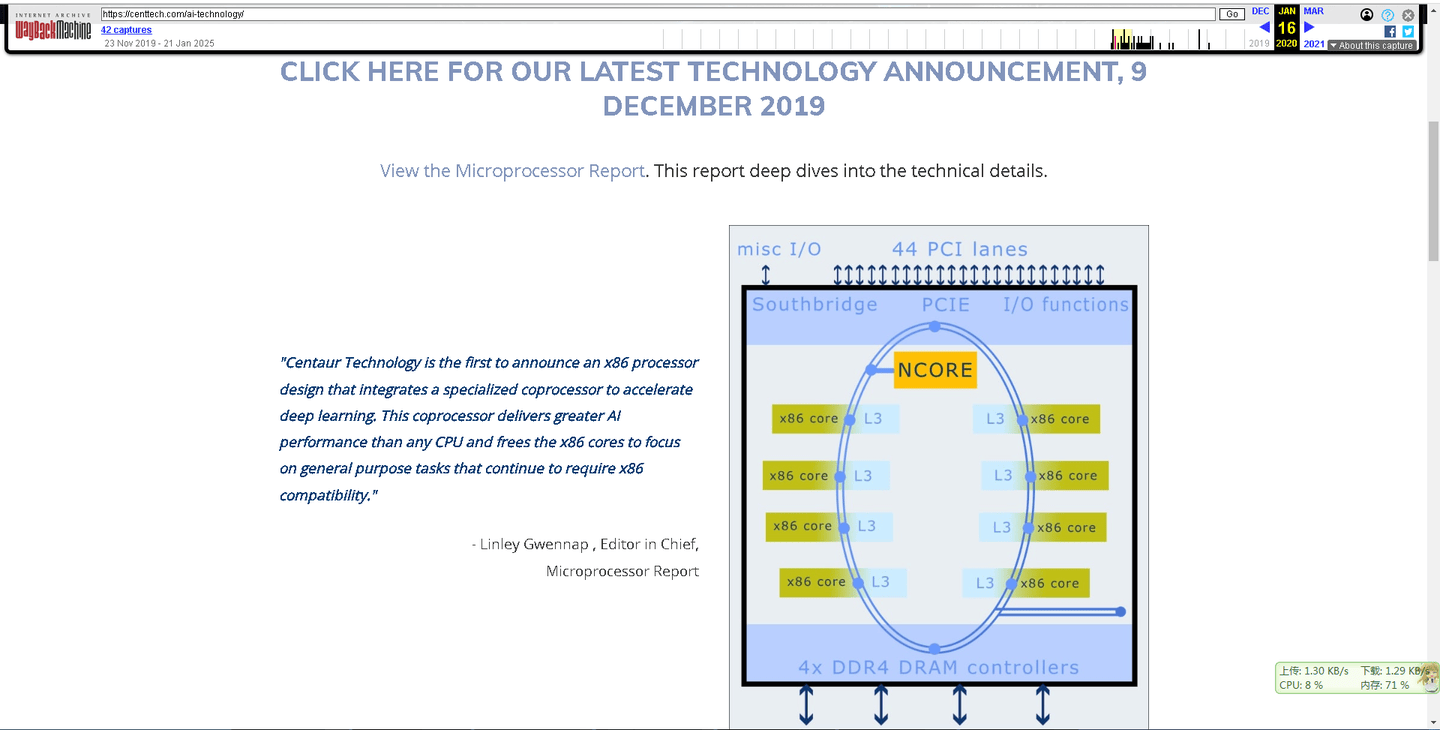


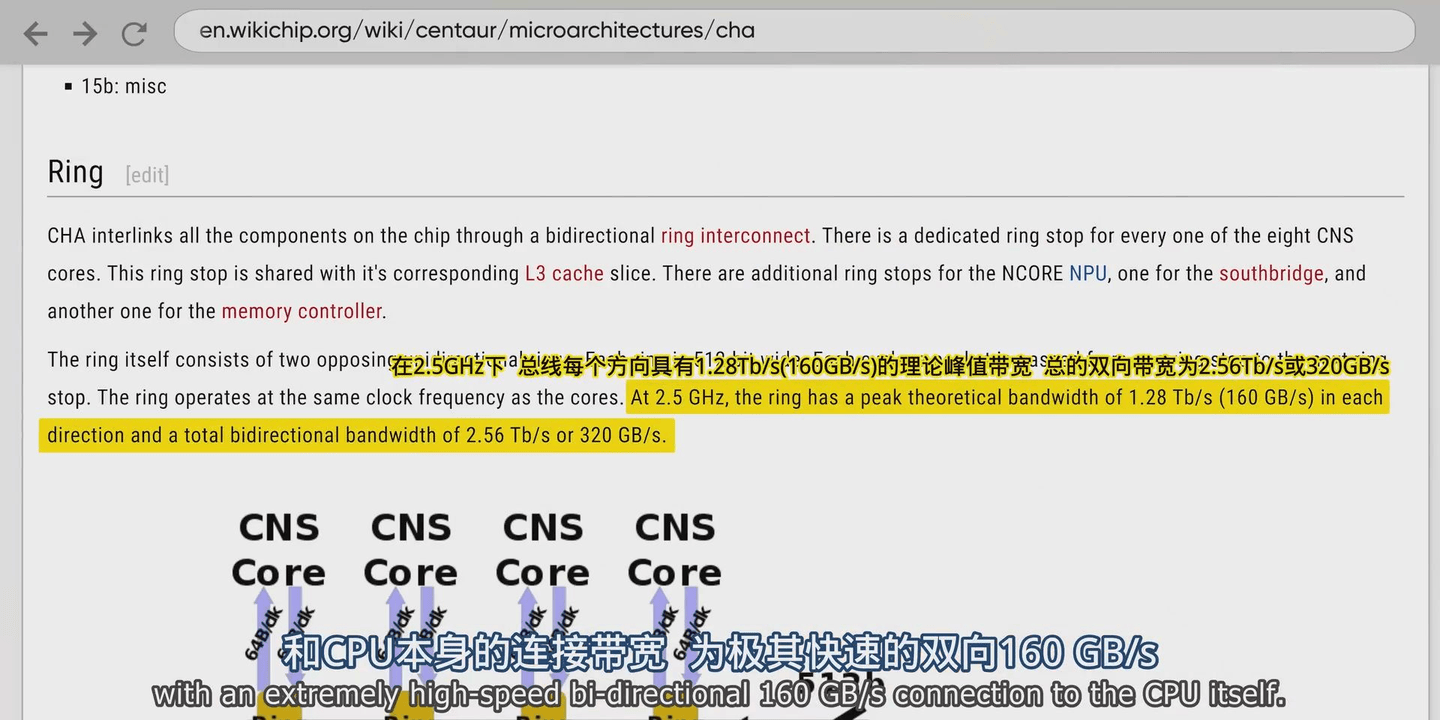

这个AI CPU虽然没发布,但是BIOS却一直在更新
即使在威盛海外研发团队被英特尔收购之前他们也一直在调试这个CNS
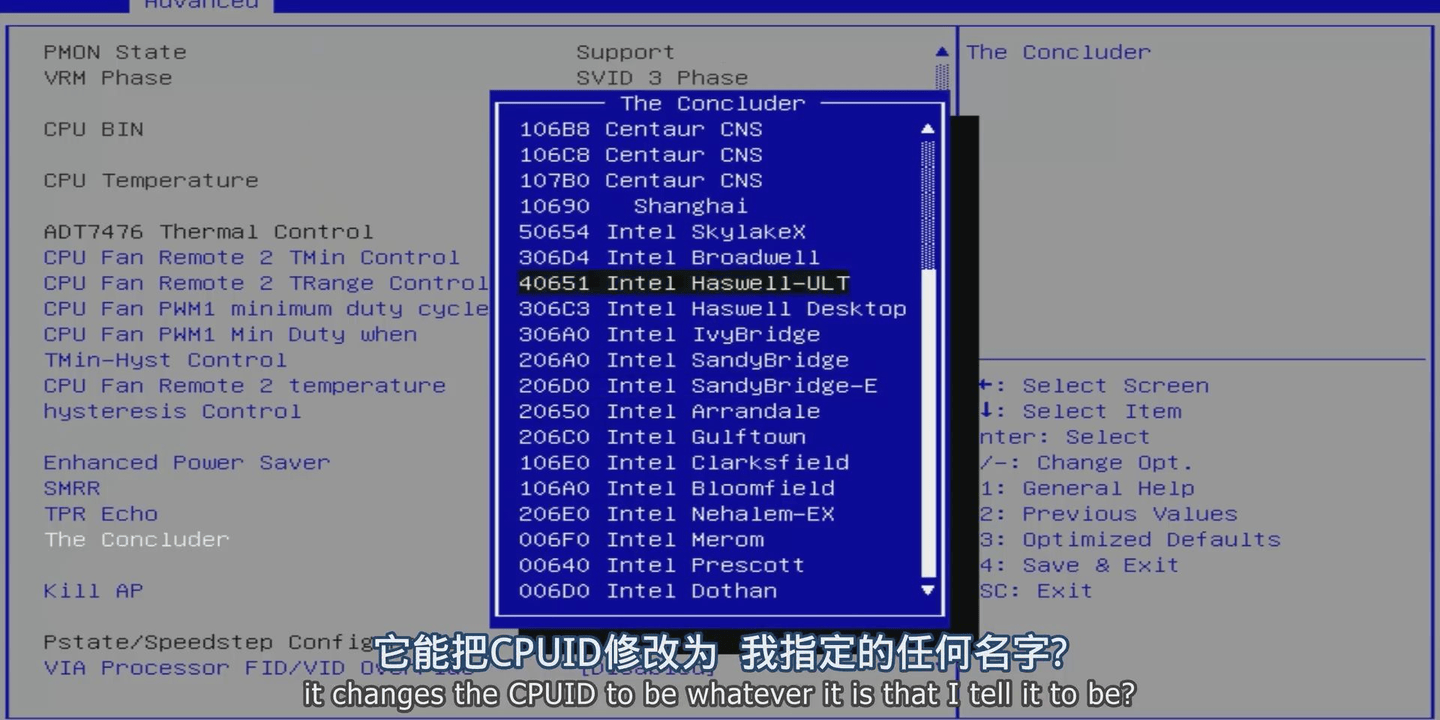
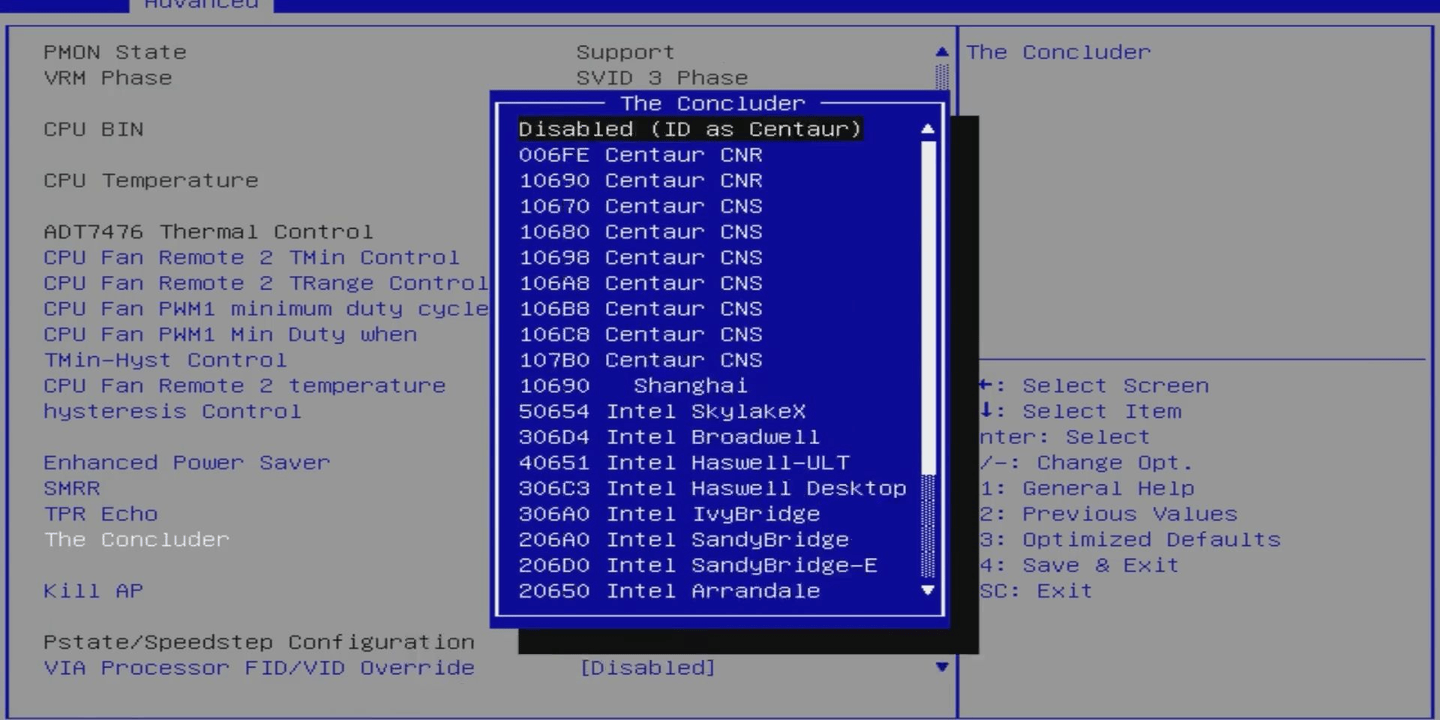
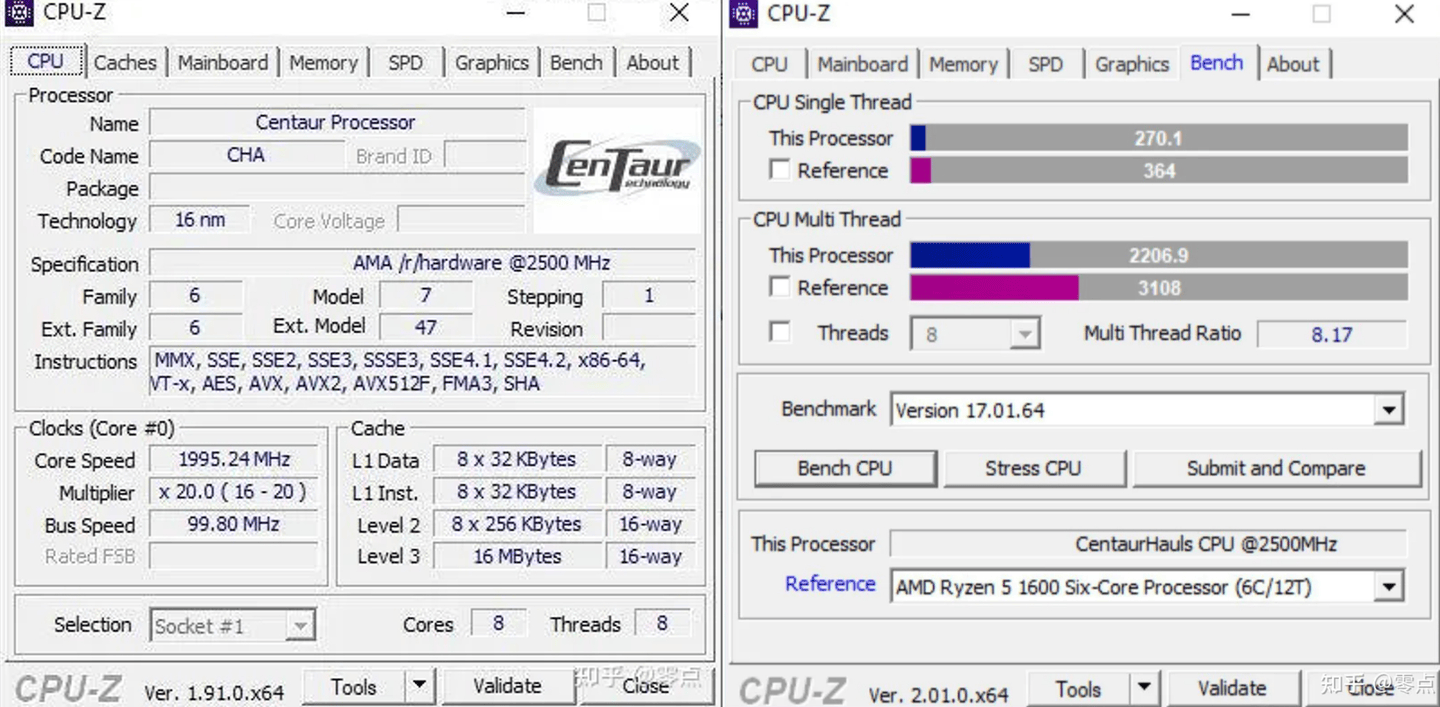
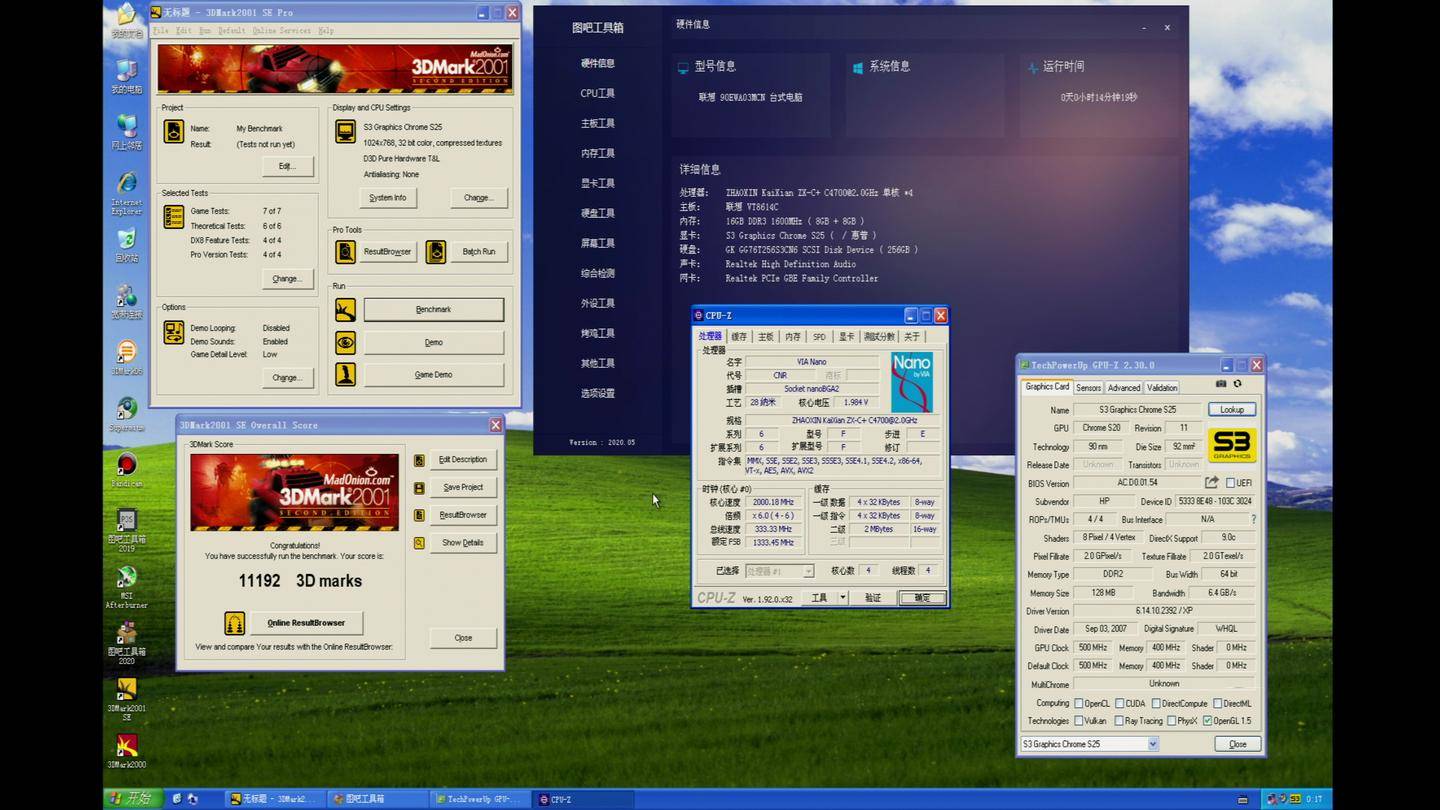
主板支持修改CPUID
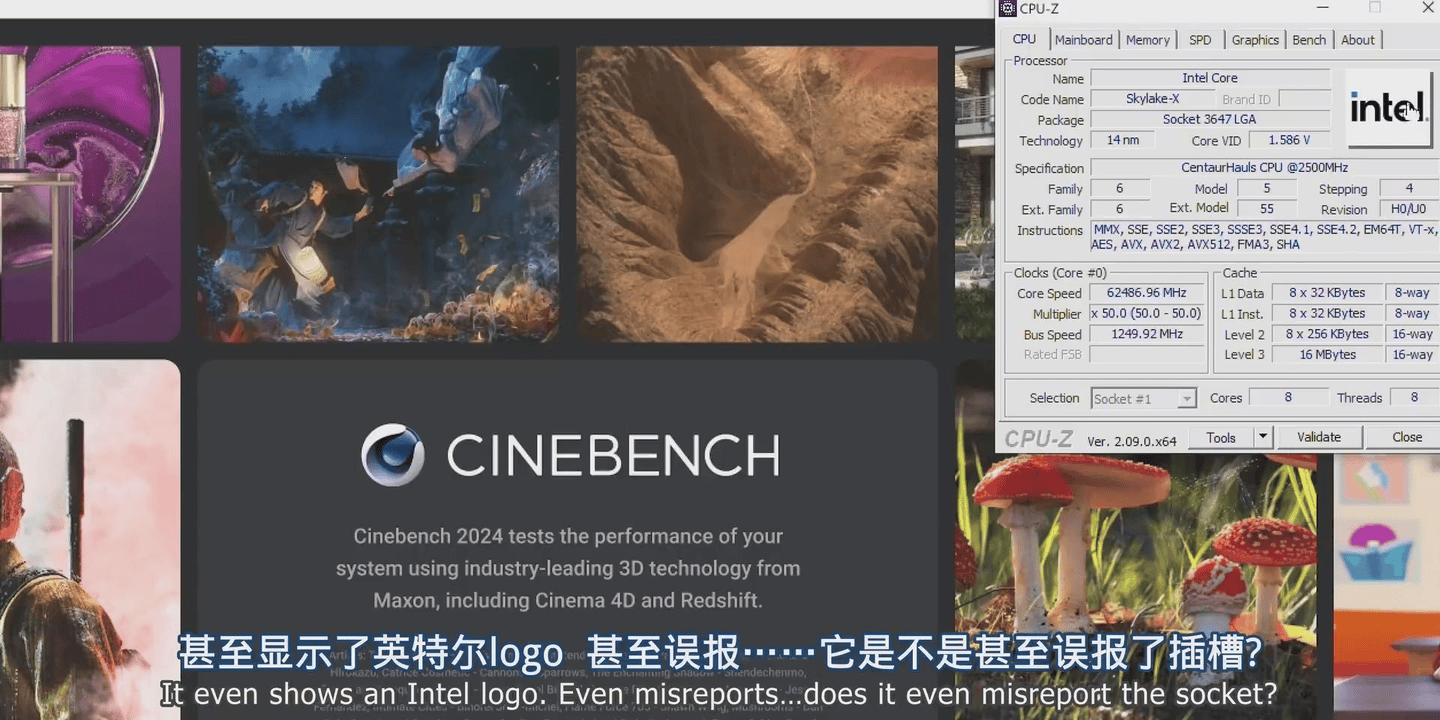
修改ID后能被识别为牢英CPU
可以看出来CPUz依然识别出来了支持AVX512
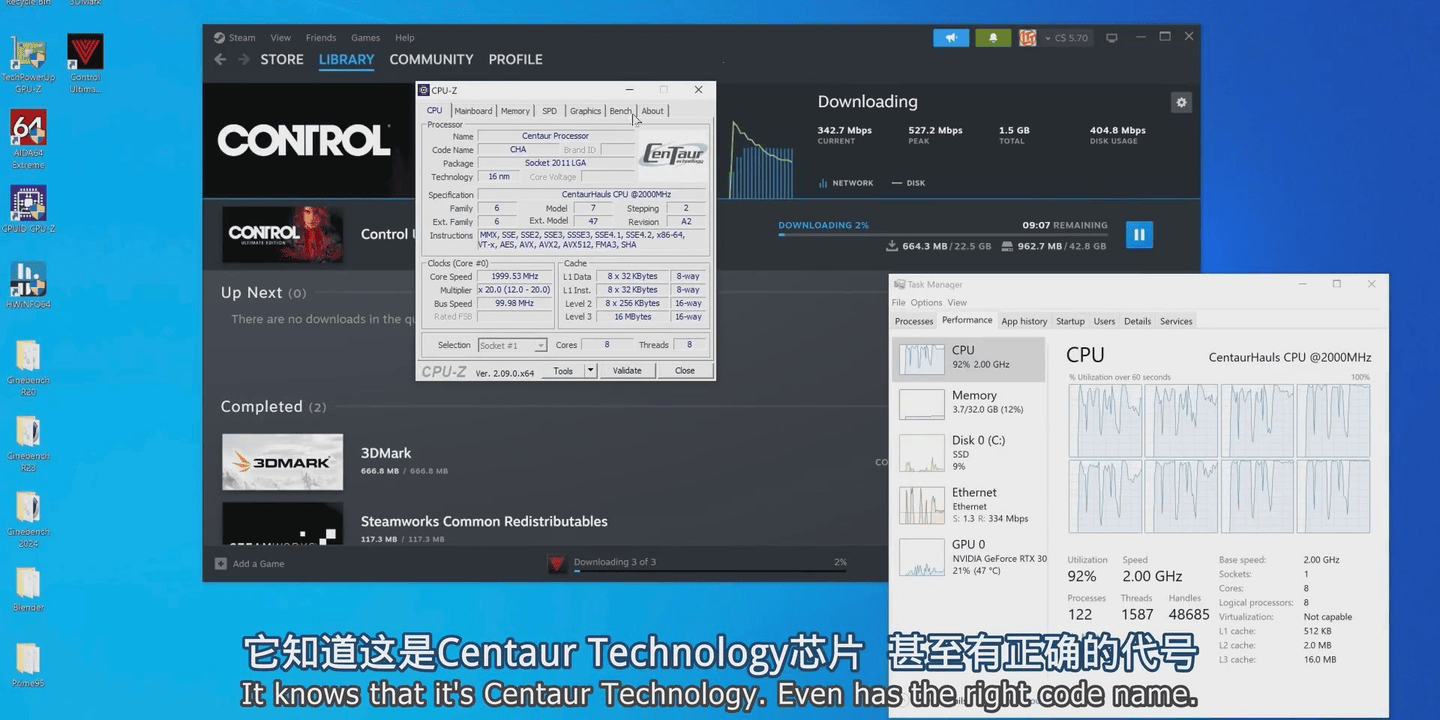
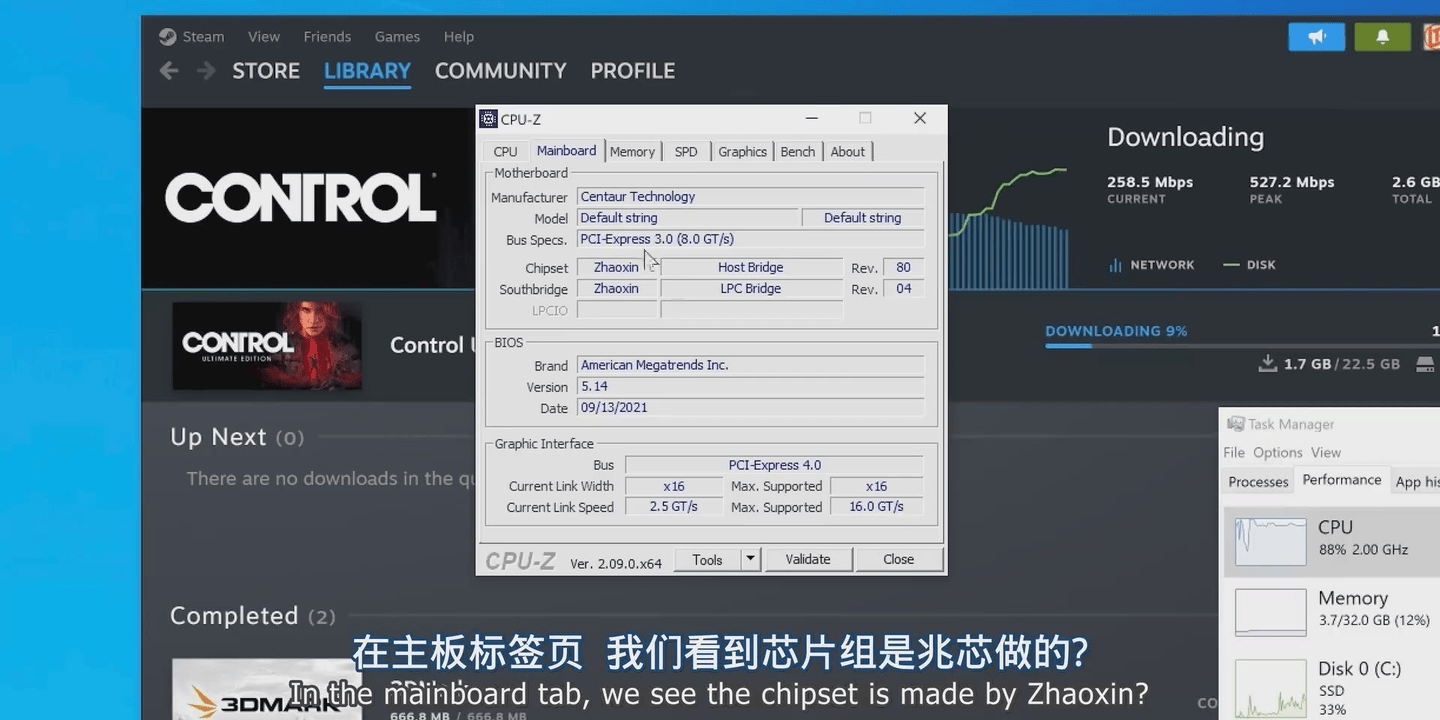
默认ID CPUz所有参数完全能正常识别
甚至在『芯片』组这页能看到是兆芯的
所以侧面证明了网传说法很可能是正确的
威盛的CNS(CHA)使用了海外研发团队的自研AI NCORE(NPU),但是CPU和IO部分却是用的兆芯的设计
不知道这个CPU的设计是不是后来的KH40000永丰,我觉得应该是
当时威盛肯定是和兆芯有什么PY交易让兆芯提供了在研阶段的CPU架构前端设计或者半成品设计以及IO以完成这个AI CPU
就像过去兆芯C4600威盛也在销售同款但是命名为C4650的CPU一样

共享了许多设计
比如很多兆芯C系列的板子不是用ZX100S『芯片』组而是VIA VX11


这里我更愿意相信威盛把VX11的『芯片』组知识产权交给了兆芯(事实上这款『芯片』组就是原威盛大陆研发团队现兆芯研发部门设计),而兆芯对威盛授权了其张江(ZX-C)CPU的IP 或者是根据某种合作协议威盛和兆芯共享了这款CPU的非涉密版本的知识产权。
后期支持SM3 SM4国密指令集的ZX-C+则威盛无法生产销售。
总之威盛和兆芯能互相使用对方的设计并不意外,因为知识产权本来就存在继承转让和共享授权的关系。
所以兆芯能通过威盛的X86交叉授权合法地设计X86 CPU而不会受专利限制。


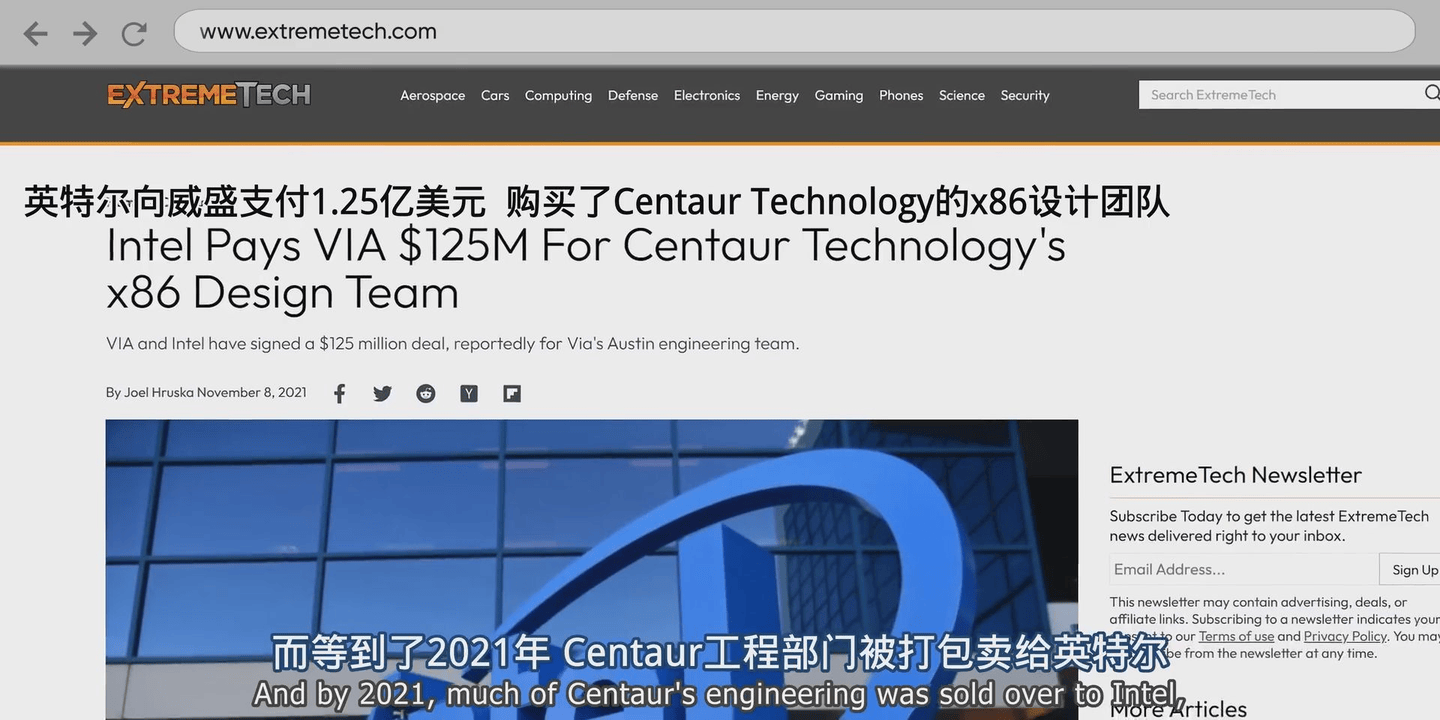
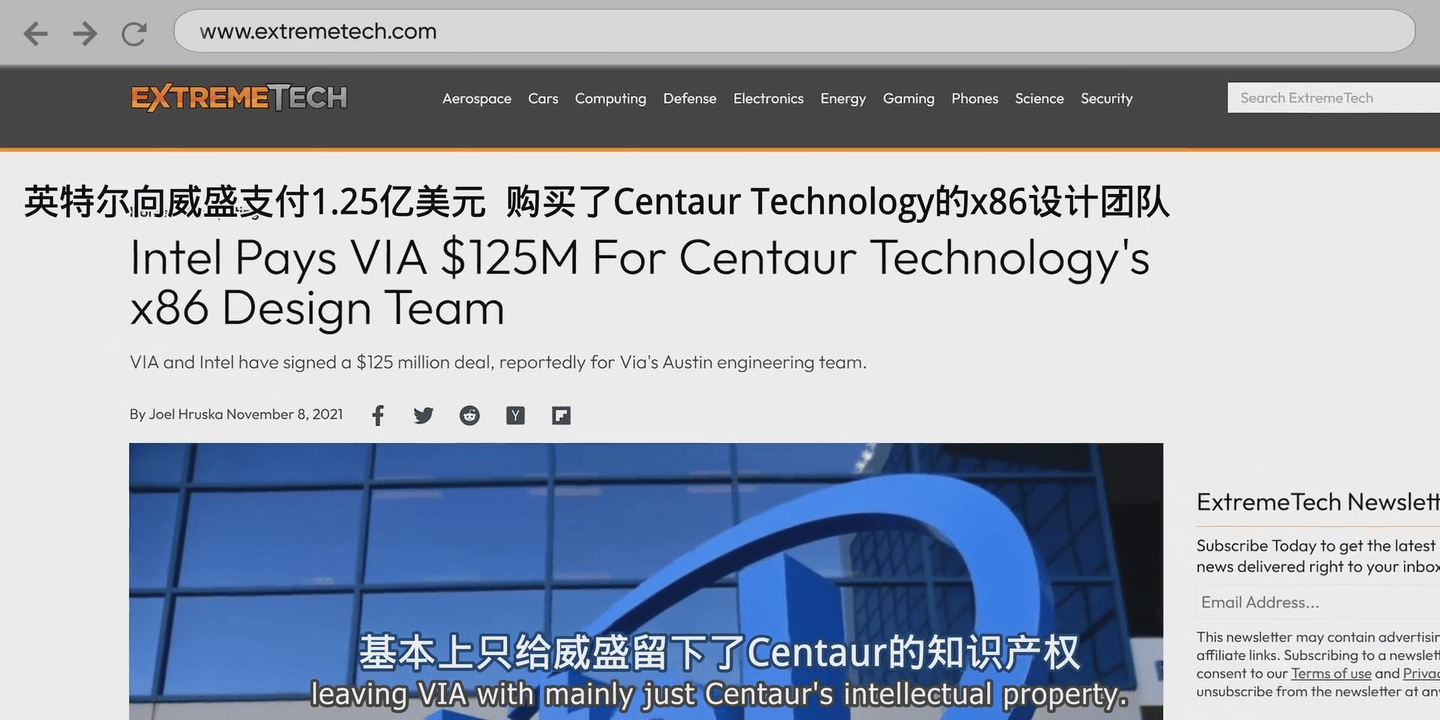

不过考虑到威盛已经把centaur半人马海外研发团队于2025年卖给了英特尔,把X86相关专利于2025年卖给了兆芯

现在自然也就不存在什么两个研发团队互相共享设计的问题了
我们可以确定的是威盛的X86交叉授权是包括含AVX512在内的所有现代X86指令相关专利的永久使用权的,而继承了这个授权的兆芯自然也完全可以设计支持所有现代X86指令的X86处理器
至于为什么最新的产品没有AVX512并不是因为没有使用权而是因为产品规划


这和牢英拥有AVX512却一度移除AVX512支持是一样的道理

顺带一提如果将VIA CNS(CHA)的CPU部分设计视为兆芯的永丰架构废案的话那么兆芯也在AVX指令集上相当于数次开倒车了
一次是从张江到五道口陆家嘴砍掉了原来就有的AVX2支持
另一次则是从CNS到永丰世纪大道砍掉了AVX512支持
当然这对于实际使用这些CPU来说并没有什么不利影响
即使是AVX2到今天也没那么普及,很多程序别说AVX2,即使没有AVX也一样能运行
大部分程序最多也就要求到SSE4那样
所以对于X86指令集支持方面也不必有什么焦虑
就这样,谢谢朋友们!



